What are the limitations of mutexes and condition variables/
- error prone / correctness / ease-of-use
- unlock wrong mutex, signal wrong condition variable
- lack of expressive power
- helper variables for access or priority control
What is a spinlock?
A spinlock is like a mutex (provides mutual exclution and it locks and unlocks) but when a process cannot obtain a lock it doesn’t relinquish the CPU, instead it spins!
What is a semaphore?
A semaphore is similar to a mutex but more general.
It’s represented by an integer. When it’s initialized it’s assigned a max value. A thread “tries” a semaphore. If it’s value is non-zero it will de decrement it and proceed, otherwise it will have to wait.
This means that multiple threads can proceed if it’s a non-binary semaphore.
What is a reader/writer lock? Why is it useful?
A reader/writer lock allows you to distinguish different kinds of access and control priority.
For example, reading (never modifying a shared resource) can be done concurrently, but writing (always modifying a shared resource) must be exclusive.
This type of lock is useful because it increases throughput over a regular (exclusive) mutex. It also ensures that writers have priority over readers to prevent writer starvation.
What is a monitor?
A high-level sychncronization construct that handles lock/unlock, signal, etc. for the programmer.
It’s also a programing style? (enter_/exit_ critical section)
Name as many synchronization constructs as you can!
What do all of these constructs have in common?
- spinlock
- monitor
- mutex + condition variable
- semaphore
- serializer
- barrier (opposite of semaphore)
- path expression
- rendezvous point
- optimistic wait-free synchronization (bets that it’s safe to allow reads to proceed concurrently)
All locks need hardware support to atomically make updates to a memory location.
Why do synchronization constructs need hardware support?
The execution of multiple threads can be interleaved and/or concurrent checks/updates of a lock’s value on different CPUs can overlap.
Therefore, we need hardware-supported atomic instructions to guarantee that only one thread can change the value of the lock at a time.
What guarantees does the hardware make about atomic instructions?
- atomic
- mutual exclusion
- queue all concurrent instructions but one
What is a shared memory multiprocessor?
How does bus-based vs interconnect-based configuration affect the system?
How are caches useful in this system?
A shared memory multiprocessor (aka symetric multiprocessors, SMPs) is when you have more than one CPU and some memory that is accessible to all the CPUs. The shared memory may be a single component or multiple components.
A bus-based configuration only one memory reference can be in flight at a time whereas an interconnect based configuration can have more than one memory reference in flight at a time.
Each of the CPUs can have caches. They’re used to hide memory latency:
- access to the cache is faster
- shared memory can add latency due to contention
What can happen w/ regard to the cache when a CPU writes? (e.g., what techniques may be used by an OS)
- no-write: we may not allow the write to the cache. instead the write will go directly to memory and the cached copy of the data will be invalidated
- write-through: the write may be applied to both the cached location and the memory location
- write-back: write applied to the cache location, but update to the memory location happens later (e.g., when the cache data is evicted)
Explain cache-hoherent (CC) vs non-cache-coherent (NCC) architecture.
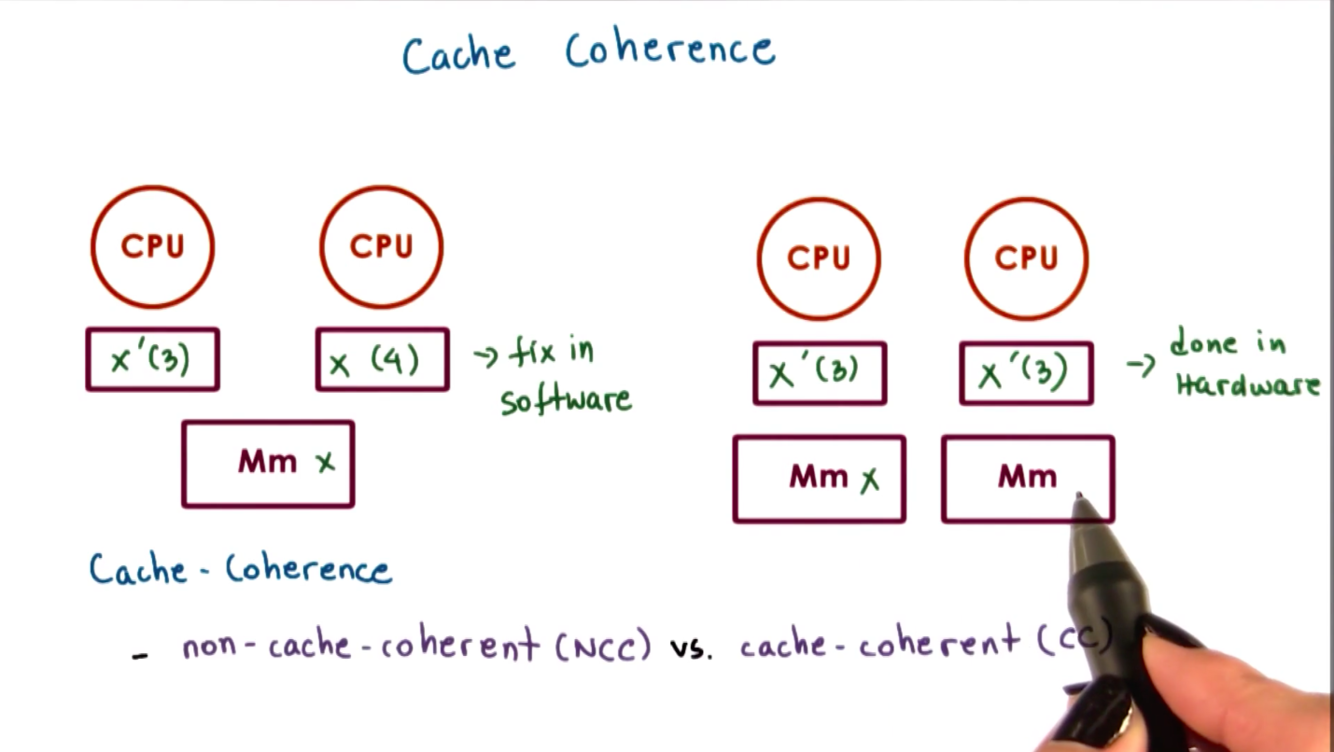
On non-cache-coherent architecture, when a CPU performs a write and its cache’s value is updated, the hardware won’t do anything to make sure this value is also updated in other CPUs caches.
On cache-coherent architecture, the hardware will take all the necessary steps to ensure that write to one cache is applied to other caches.
What happens with cache coherence with atomic instructions are used?
Atomic operations always bypass caches and are issued directly to the memory controller.
This allows them to be ordered and sychronized, avoiding race conditions.
But this means atomic instructions will take much longer and we also generate coherence traffic (update or invalidate all cached copies) regardless of change.
Are atomic instructions more expensive on single or multiple CPU systems?
Atomic instructions are more expensive on multi-CPU systems because of:
- memory contention
- cache bypass
- coherence traffic
What is a test_and_test_and_set spinlock?
Pros / Cons?
A test_and_test_and_set (aka spin on read, aka spin on cached value) spinlock tests the cached value of lock in its while loop rather than the atomic test_and_set method. Only then if the cached value of lock is free will it call the atomic test_and_set method. This avoids the contention from calling test_and_set until it’s absolutely necessary.
Pros
+ Latency is improved over test_and_set spinlock
+ Delay is improved over test_and_set spinlock
Cons
- Contention may be better but…
- non-cache-coherent architecture => no difference
- cache-coherent architecture + write update => OK (every attempt to aquire the lock generates content for the memory module, updates the cache)
- cache-coherent architecutre + write invalidate => BAD (every attempt to aquire the lock generates contention for the memory module and creates invalidation traffic: invalidates the cache so we have to go to memory for the new value thus creating more memory contention)
In summary, poor performance of this lock is due to:
- everyone sees lock is free at the same time
- everyone tries to acquire the lock at the same time
What is a spinlock “delay”?
Pros/Cons?
A delay after lock release
- everyone sees lock is free
- not everyone attempts to aquire it
Pros
+ contention is improved
+ latency is ok
Cons
- delay is much worse
Pros/Cons of static vs dynamic delay for a “delay” spinlock?
Static Delay (based on fixed value, e.g., CPU ID)
+ simple approach
- unneccesary delay under low contention
Dynamic Delay (backoff-based)
+ random delay in a range that increases with “perceived” contention (perceived = failed test_and_set)
- delay after each reference will keep growing based on contention OR long critical section
What is a queuing lock?
Pros/Cons?
An attempt to aquire a lock issues a ticket for a thread, which is assigned a private lock.
A thread can enter the critical section when its queue ticket value is has_lock. A thread signals the next lock holder on exit.
Pros
+ delay: directly signal next CPU / thread to run
+ contention: better! b/c the atomic operation is only executed once when a thread attempts to acquire the lock and it’s not part of the while loop. plus the atomic instructions and the spining are done on different variables but requires cache coherence and cacheline aligned elements
Cons
- needs read_and_increment atomic operation, but this is much less common across operating systems than try_and_set
- O(N) size
- latency: more costly read_and_increment operation
In summary:
only 1 CPU/thread sees the lock is free and tries to acuire the lock
-
P1L2. Introduction to Operating Systems16
-
P2L1. Processes and Process Management26
-
P2L2. Threads and Concurrency28
-
P2L4. Thread Design Considerations18
-
Midterm31
-
P2L5. Thread Performance Considerations8
-
P3L1. Scheduling33
-
P3L2. Memory Management22
-
P3L3. Inter-Process Communication9
-
P3L4. Synchronization Constructs17
-
P3L5. I/O Management18
-
P3L6. Virtualization15
-
P4L1. Remote Procedure Calls9
-
P4L2. Distributed File Systems12
-
P4L3. Distributed Shared Memory15
-
P4L4. Datacenter Technologies7
-
Final48
