li径向基核函数 (Radial basis function)
- 径向基函数是一个取值仅依赖于到原点距离的实值函数,即。此外,也可以按到某一中心点c的距离来定义, 即。任一满足的函数都可称作径向函数。其中,范数一般为欧几里得距离,不过亦可使用其他距离函数。 可以用于许多向函基数的和来逼近某一给定的函数。这一逼近的过程可看作是一个简单的神经网络。
- from sklearn.svm import SVR: regressor=SVR(kernel=’rbf’)
- most important SVR parameter is kernel type. It can be linar, polynomial or gussian SVR. 高斯就是rbf
- https://en.wikipedia.org/wiki/Radial_basis_function

径向基函数网络 (Radial basis function network)
- https://towardsdatascience.com/radial-basis-functions-neural-networks-all-we-need-to-know-9a88cc053448
- In the field of mathematical modeling, a radial basis function network is an artificial neural network that uses radial basis functions as activation functions. The output of the network is a linear combination of radial basis functions of the inputs and neuron parameters.
- standardization标准化
- 公式
- python code
- scale归一化
- 公式
- python code
- 标准化操作(standardization)是将数据按其属性(按列)减去平均值,然后再除以方差。这个过程从几何上理解就是,先将坐标轴零轴平移到均值这条线上,然后再进行一个缩放,涉及到的就是平移和缩放两个动作。这样处理以后的结果就是,对于每个属性(每列)来说,所有数据都聚集在0附近,方差为1。计算时对每个属性/每列分别进行。
- (X-mean)/std
- from sklearn.preprocessing import StandardScaler
- 它是一种缩放就行。归一化操作的过程,首先是把某个属性(按列)的最大值和最小值之间的距离看成是单位1,然后再看x和最小值的距离占总距离的比例。所以它总是一个处于0到1之间的百分数。
- (X-min)/(max-min)
- from sklearn.preprocessing import MinMaxScaler
sklearn.preprocessing
- fit()
- transform()
- fit_transform()
- inverse_transform()
- fit(): Method calculates the parameters μ and σ and saves them as internal objects. 解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
- transform(): Method using these calculated parameters apply the transformation to a particular dataset.
解释:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。 - fit_transform(): joins the fit() and transform() method for transformation of dataset.
解释:fit_transform是fit和transform的组合,既包括了训练又包含了转换。
transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等) - 将标准化后的数据转换为原始数据。
- reshape(1,-1)
- reshape(2,-1)
- reshape(-1,1)
- reshape(-1,2)
- reshape(N, -1)
- reshape(-1, N)
- -1
- numpy.arange(a,b,c)
- reshape(1,-1)转化成1行:
- reshape(2,-1)转换成两行:
- reshape(-1,1)转换成1列:
- reshape(-1,2)转化成两列
- reshape(N, -1)指定N行,列数自动确定
- reshape(-1, N)生成N列,行数自动确定
- -1的作用就在此: 自动计算d:d=数组或者矩阵里面所有的元素个数/c, d必须是整数,不然报错)
- numpy.arange(a,b,c) 从 数字a起, 步长为c, 到b结束,生成array
support vector regression 支持向量机
https://www.saedsayad.com/support_vector_machine_reg.htm
- Support Vector Machine can also be used as a regression method, maintaining all the main features that characterize the algorithm (maximal margin). The Support Vector Regression (SVR) uses the same principles as the SVM for classification, with only a few minor differences. First of all, because output is a real number it becomes very difficult to predict the information at hand, which has infinite possibilities. In the case of regression, a margin of tolerance (epsilon) is set in approximation to the SVM which would have already requested from the problem. But besides this fact, there is also a more complicated reason, the algorithm is more complicated therefore to be taken in consideration. However, the main idea is always the same: to minimize error, individualizing the hyperplane which maximizes the margin, keeping in mind that part of the error is tolerated.
- 在机器学习中,支持向量机是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
- 除了进行线性分类之外,SVM还可以使用所谓的核技巧有效地进行非线性分类,将其输入隐式映射到高维特征空间中。 当数据未被标记时,不能进行监督式学习,需要用非监督式学习,它会尝试找出数据到簇的自然聚类,并将新数据映射到这些已形成的簇。将支持向量机改进的聚类算法被称为支持向量聚类[2],当数据未被标记或者仅一些数据被标记时,支持向量聚类经常在工业应用中用作分类步骤的预处理。
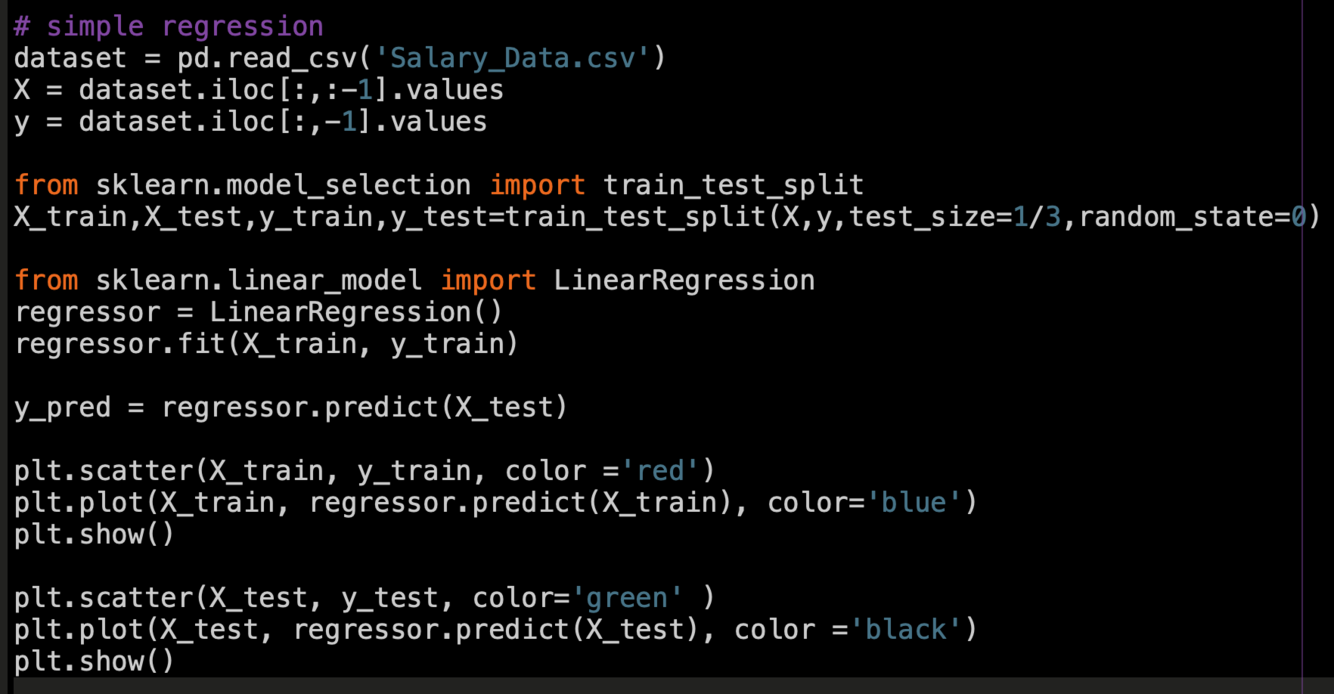
simple regression
multiple linear regression

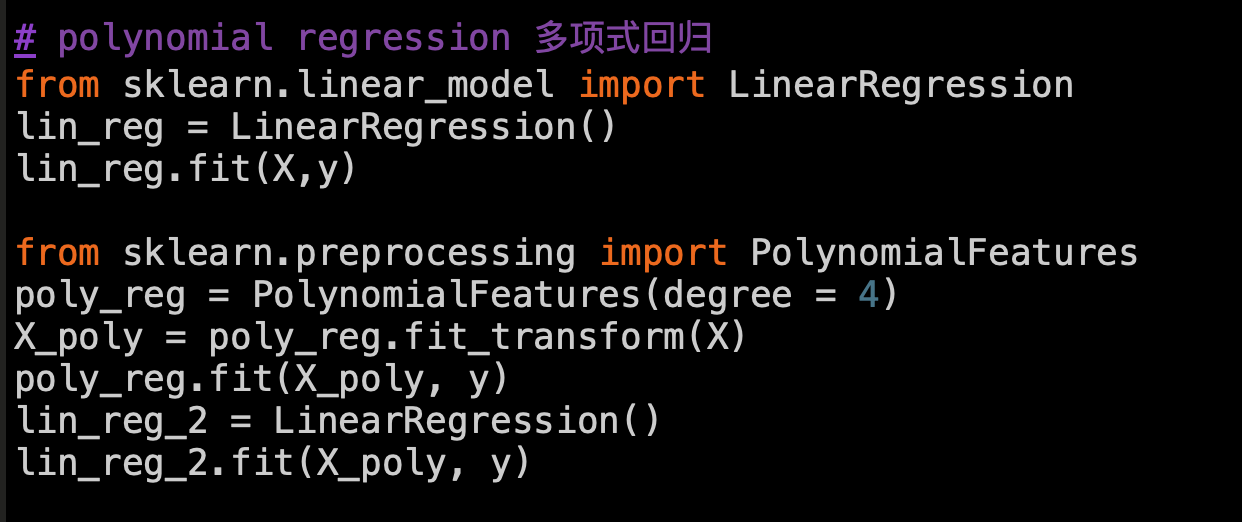
polynomial regression 多项式回归
X = [[1] [2] [3] [4] [5] [6] [7] [8] [9] [10]]
y = [45000 50000 60000 80000 110000 150000 200000 300000 500000
1000000]
Polynomial Regression is a form of linear regression in which the relationship between the independent variable x and dependent variable y is modeled as an nth degree polynomial. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x)
https://www.geeksforgeeks.org/python-implementation-of-polynomial-regression/
support vector regression 支持向量机
X = [[1] [2] [3] [4] [5] [6] [7] [8] [9] [10]]
y = [45000 50000 60000 80000 110000 150000 200000 300000 500000
1000000]

Decision Tree regression
X = [[1] [2] [3] [4] [5] [6] [7] [8] [9] [10]]
y = [45000 50000 60000 80000 110000 150000 200000 300000 500000
1000000]
Decision tree builds regression or classification models in the form of a tree structure. It breaks down a dataset into smaller and smaller subsets while at the same time an associated decision tree is incrementally developed. The final result is a tree with decision nodes and leaf nodes.

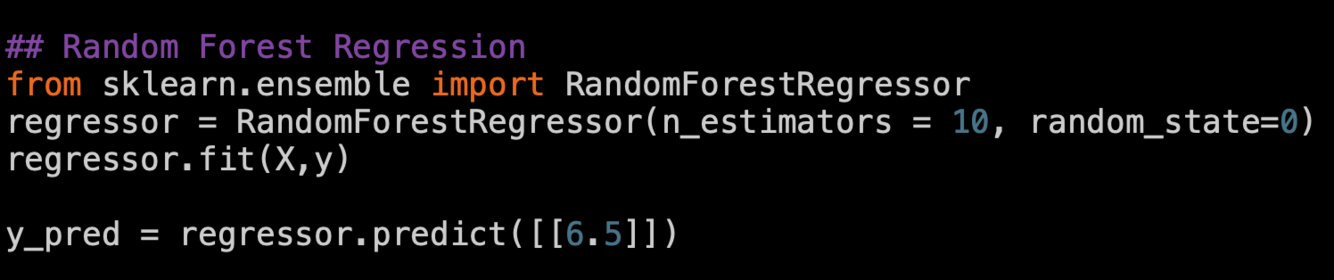
Random Forest Regression
X = [[1] [2] [3] [4] [5] [6] [7] [8] [9] [10]]
y = [45000 50000 60000 80000 110000 150000 200000 300000 500000
1000000]
Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Random decision forests correct for decision trees’ habit of overfitting to their training set.
logistic regression
逻辑回归
- a solution for classification
- logistic function
https://christophm.github.io/interpretable-ml-book/logistic.html
- In statistics, the logistic model is used to model the probability of a certain class or event existing such as pass/fail, win/lose, alive/dead or healthy/sick. This can be extended to model several classes of events such as determining whether an image contains a cat, dog, lion, etc. Each object being detected in the image would be assigned a probability between 0 and 1 and the sum adding to one.
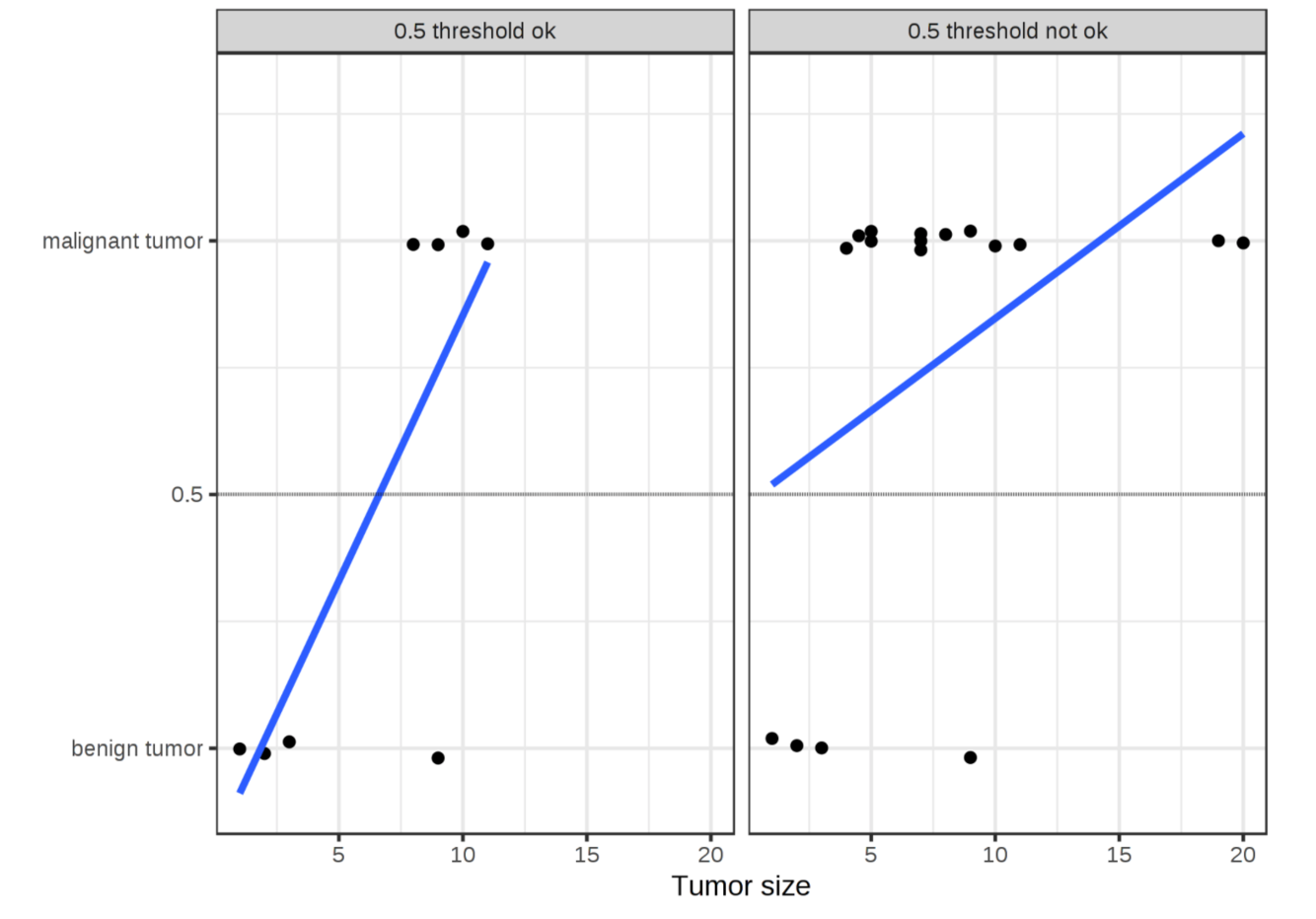
- linear regression不适用于classification:
- 线性回归不产出probabilities,有可能推导出的可能性结果小于0或大于1.
- 看配图:数据的分布会影响回归结果,对于判断肿瘤是否为良性,图片里是否有狗等是否问题,需要用classification.
- Theory:
- Instead of fitting a straight line or hyperplane, the logistic regression model uses the logistic function to squeeze the output of a linear equation between 0 and 1. The logistic function is defined as:
Confusion matrix
混淆矩阵
https://www.geeksforgeeks.org/confusion-matrix-machine-learning/
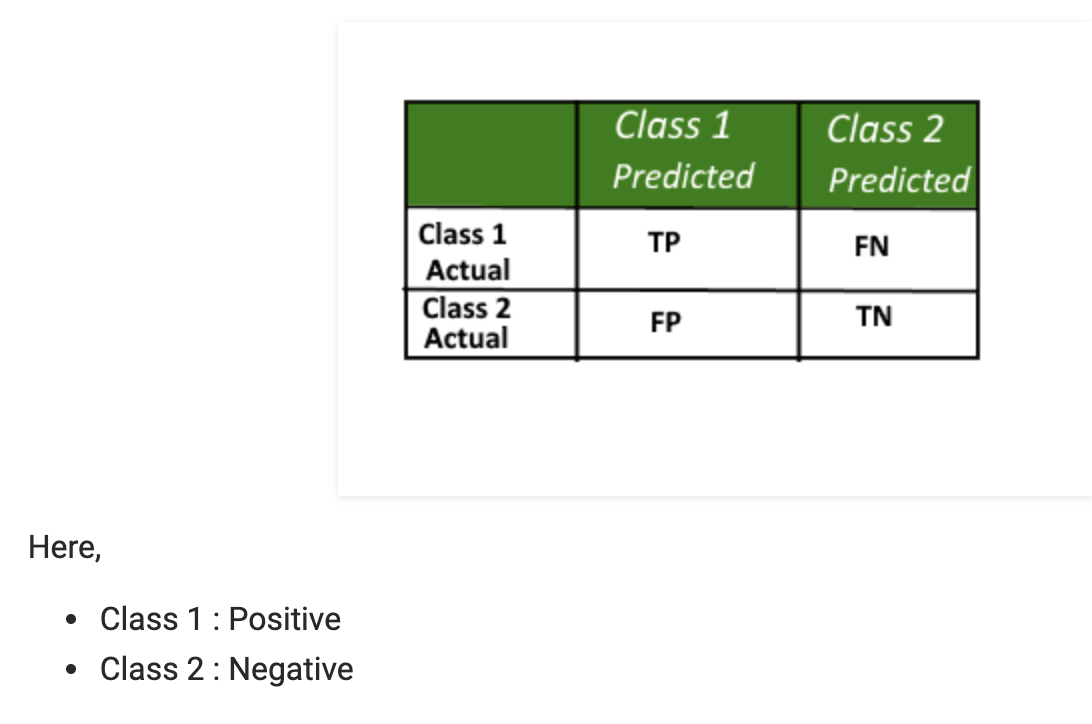
A confusion matrix is a summary of prediction results on a classification problem. The number of correct and incorrect predictions are summarized with count values and broken down by each class. This is the key to the confusion matrix. The confusion matrix shows the ways in which your classification model is confused when it makes predictions. It gives us insight not only into the errors being made by a classifier but more importantly the types of errors that are being made.
Supervised Learning
监督式学习
- 定义:In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
- 有数据库
- 知道正确的输出是什么样的
- 关于输入和输出的关系是有想法的
- 分类:
- Regression: to predict results within a continuous output
- classification: to predict results in a discrete output
Unsupervised learning
无监督式学习
- Definition: Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don’t necessarily know the effect of the variables.
- We can derive this structure by clustering the data based on relationships among the variables in the data.
- With unsupervised learning there is no feedback based on the prediction results.
- 应用:
- Organize computing clusters
- Social network analysis
- Market segmentation
- Astronomical data analysis
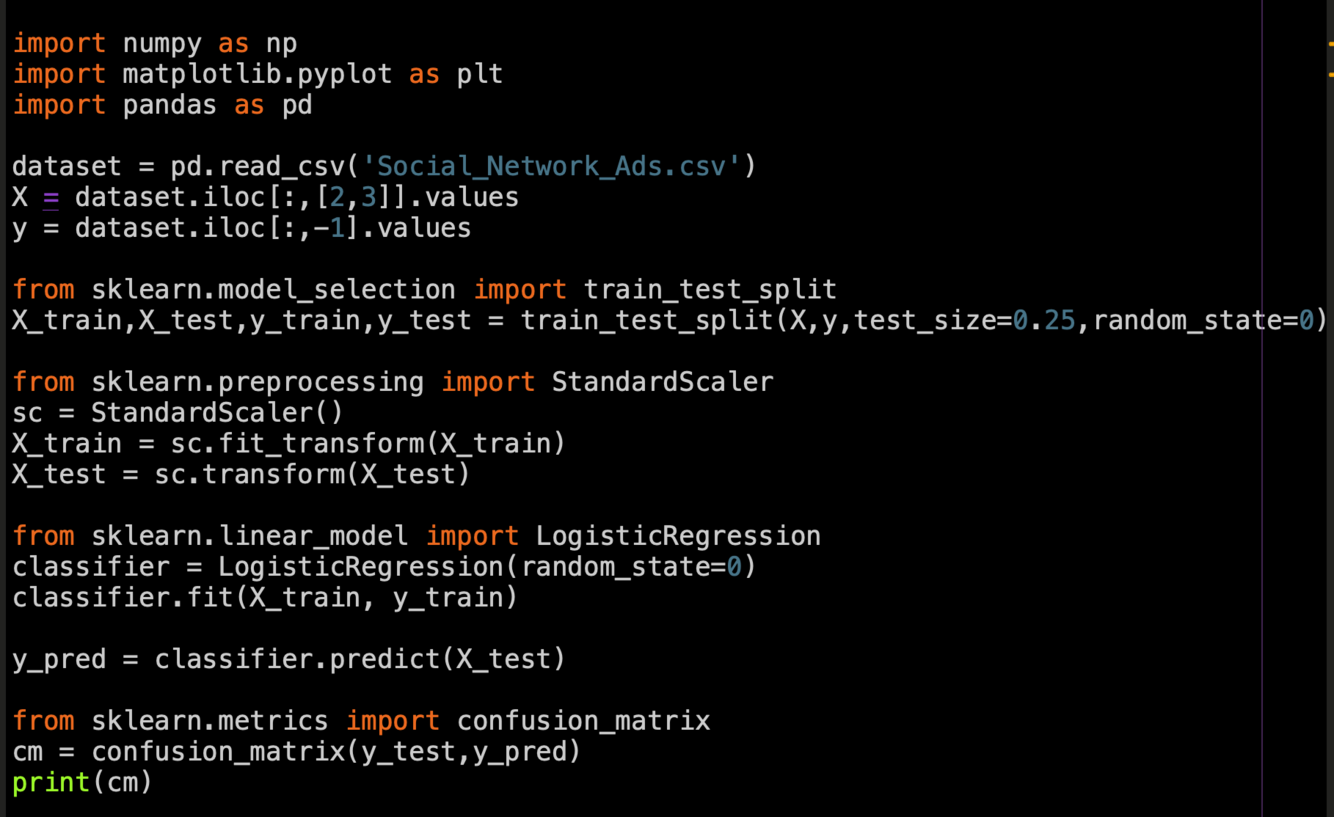
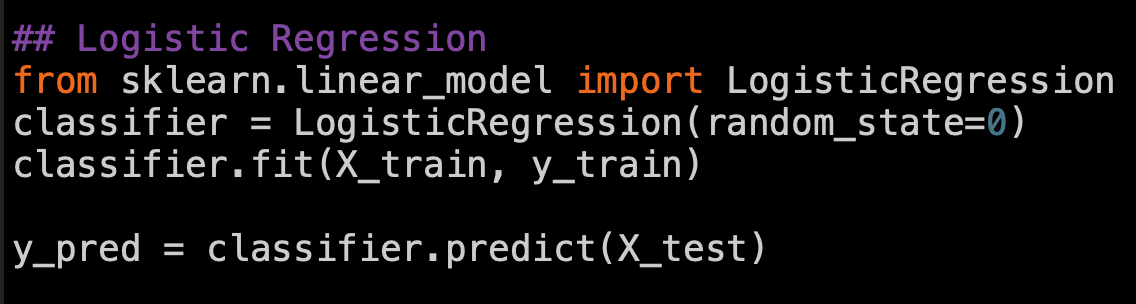
Logistic Regression
Python code
k-nearest neighbors algorithm
K-近邻算法
https://www.saedsayad.com/k_nearest_neighbors.htm
K nearest neighbors is a simple algorithm that stores all available cases and classifies new cases based on a similarity measure (e.g., distance functions). KNN has been used in statistical estimation and pattern recognition already in the beginning of 1970’s as a non-parametric techniqu
SVM and Kernel SVM
https://towardsdatascience.com/svm-and-kernel-svm-fed02bef1200
- SVM是十大top AI算法之一,deal with非线性和高维
- it is a supervised learning algorithm
- it mostly used for classification but it can be used also for regression.
- The main idea is that based on the labeled data (training data) the algorithm tries to find the optimal hyperplane which can be used to classify new data points. In two dimensions the hyperplane is a simple line.
- The main idea is that based on the labeled data (training data) the algorithm tries to find the optimal hyperplane which can be used to classify new data points. In two dimensions the hyperplane is a simple line.
- As an example, lets consider two classes, apples and lemons.
- Other algorithms will learn the most evident, most representative characteristics of apples and lemons, like apples are green and rounded while lemons are yellow and have elliptic form.
- In contrast, SVM will search for apples that are very similar to lemons, for example apples which are yellow and have elliptic form. This will be a support vector. The other support vector will be a lemon similar to an apple (green and rounded). So other algorithms learnsthe differences while SVM learns similarities.
Logistic Regression
K-Nearest Neighbors

Support Vector Machine
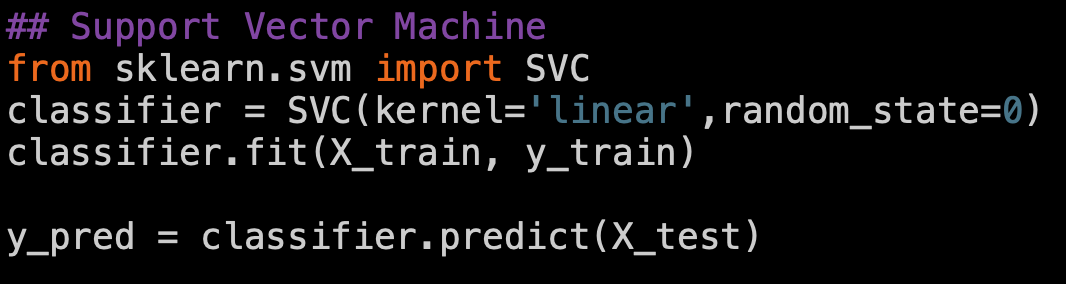
kernel Suppoort Venctor Machine

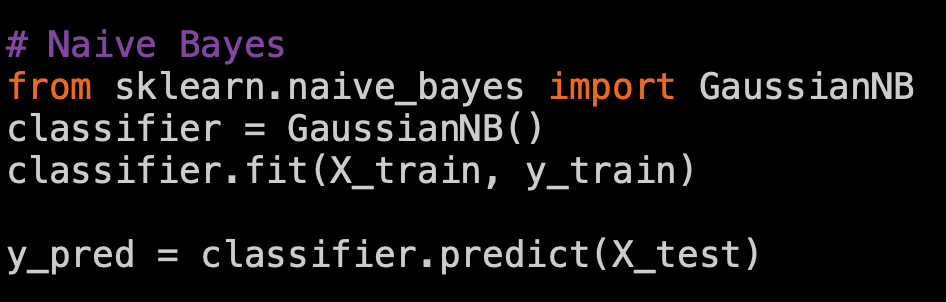
Naive Bayes