- Deskriptive Biostatistik
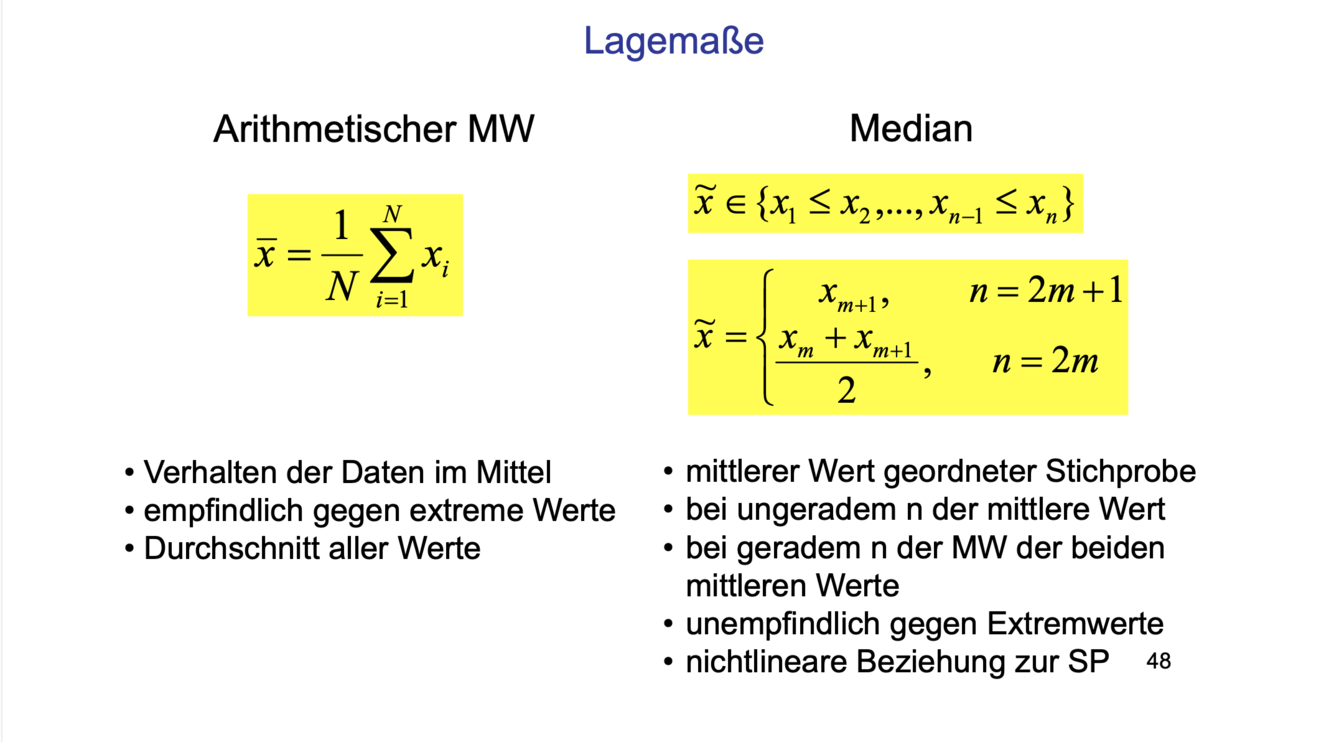
Lagemaße
Arithmetischer MW
Median
- Deskriptive Biostatistik
getrimmter Mittelwert
- Der getrimmte Mittelwert ist eng mit dem arithmetischen Mittel verwandt. Im Gegensatz zu diesem wird bei dem getrimmten Mittelwert ein gewisser Anteil der größten und der kleinsten Stichprobenelemente ignoriert. Daher ist das getrimmte Mittel robuster als das arithmetische Mittel, verändert sich also weniger bei Modifikationen der Stichprobe.
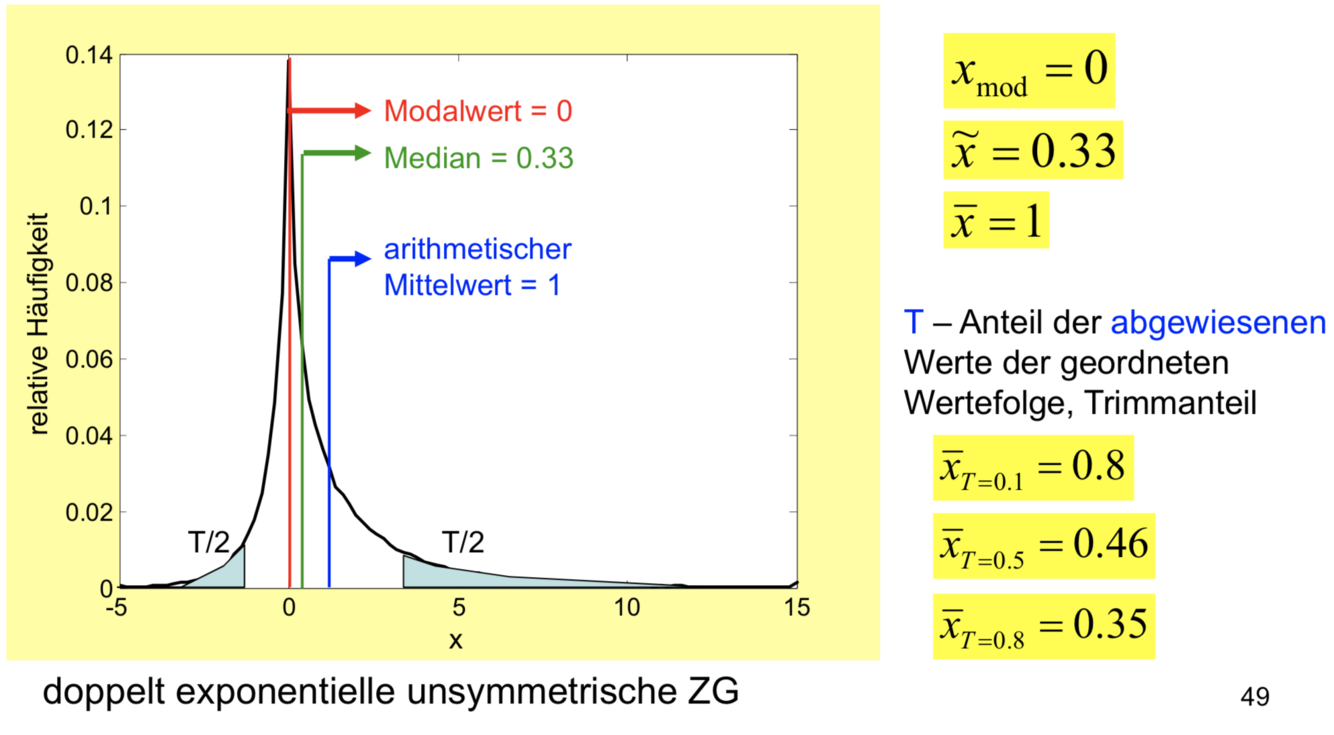
- Der Wert, bei dem die Häufigkeit ihr Maximum erreicht, wird als Modalwert bezeichnet. Bei einer zusammengesetzten Verteilung kann es mehrere (lokale) Modalwerte geben (ähnlich wie lokale Maxima).
- Der Median liegt dicht am Modalwert mit 0.33.
- Der arithmetische Mittelwert liegt mit 1.0 weit entfernt vom Modalwert und vom Median und charakterisiert die Lage der Verteilung nur schlecht. Hier wird deutlich, wie empfindlich der arithmetische MW bei Extremwerten (Rechtsausschläge) ist.
- Am besten kommt der Median in die Nähe des Maximums. Allerdings ist der Median ein nichtlineares Maß und daher für die Analyse denkbar ungeeignet. Zumal die im Folgenden behandelten Streumaße sich auf den Mittelwert beziehen. Daher versucht man den MW – der ein lineares Maß ist – so zu trimmen, dass zwar die Operation linear bleibt, man aber trotzdem näher an das Maximum kommt.
- Trimmen bedeutet, dass man einen Anteil T (0 bis 1) der kleinsten bzw. größten Werte (der geordneten Stichprobe) aus der Berechnung des MW ausschließt. Wie den Zahlenbeispielen zu entnehmen ist, je höher der Anteil der abgewiesenen Werte ist, umso mehr nähert man sich dem Median. So lässt sich der Median auch interpretieren: es ist der letzte nicht abgewiesen Wert beim totalen symmetrischen Trimmen.
- Welchen Anteil man bei einer konkreten Aufgabe trimmt, ist ein rein empirisches Problem, wie so oft in der Statistik.
- Deskriptive Biostatistik
Streumaße
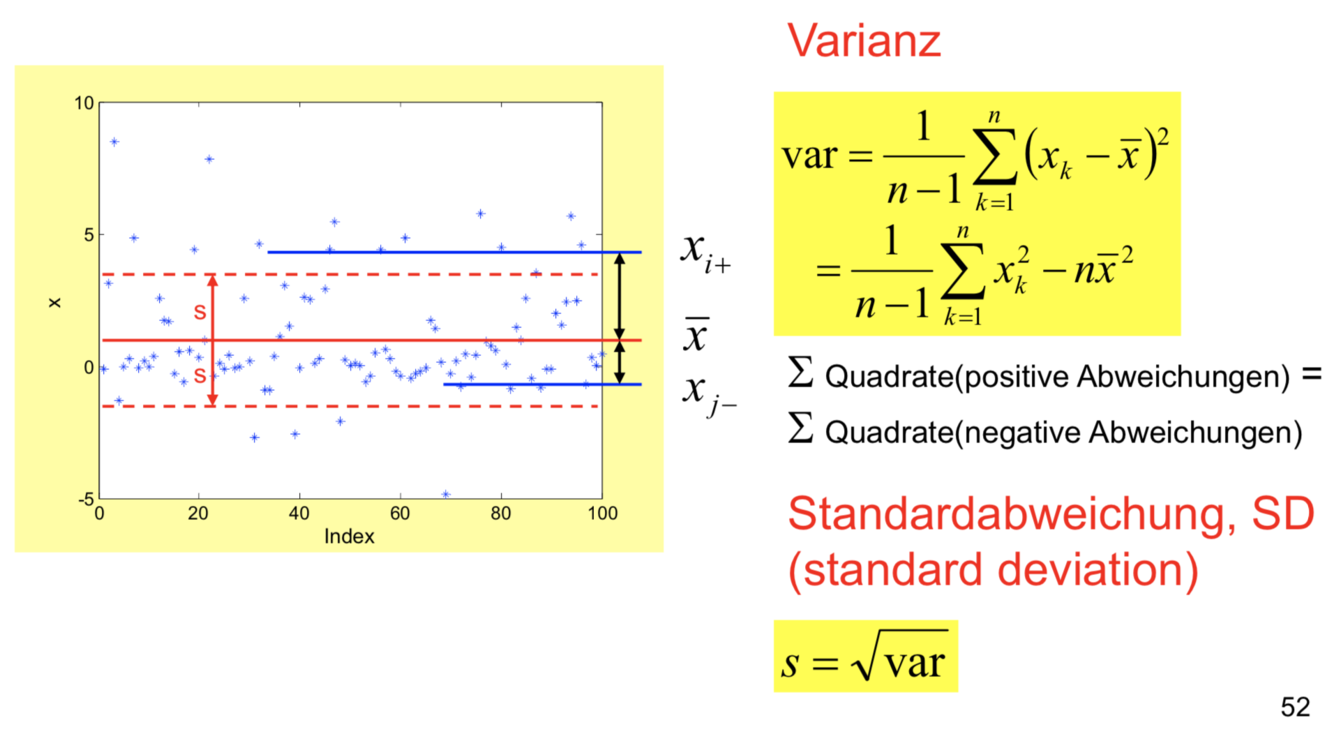
Varianz
Die Varianz gibt den mittleren Abstand der Messwerte vom Mittelwert an, ist also ein Maß für die Breite der Verteilung der Daten. Da sie auf den MW bezogen (zentriert) ist , ist sie von der Lage der Verteilung unabhängig, und heißt daher auch zweites zentrales Moment.
- Deskriptive Biostatistik
Streumaße
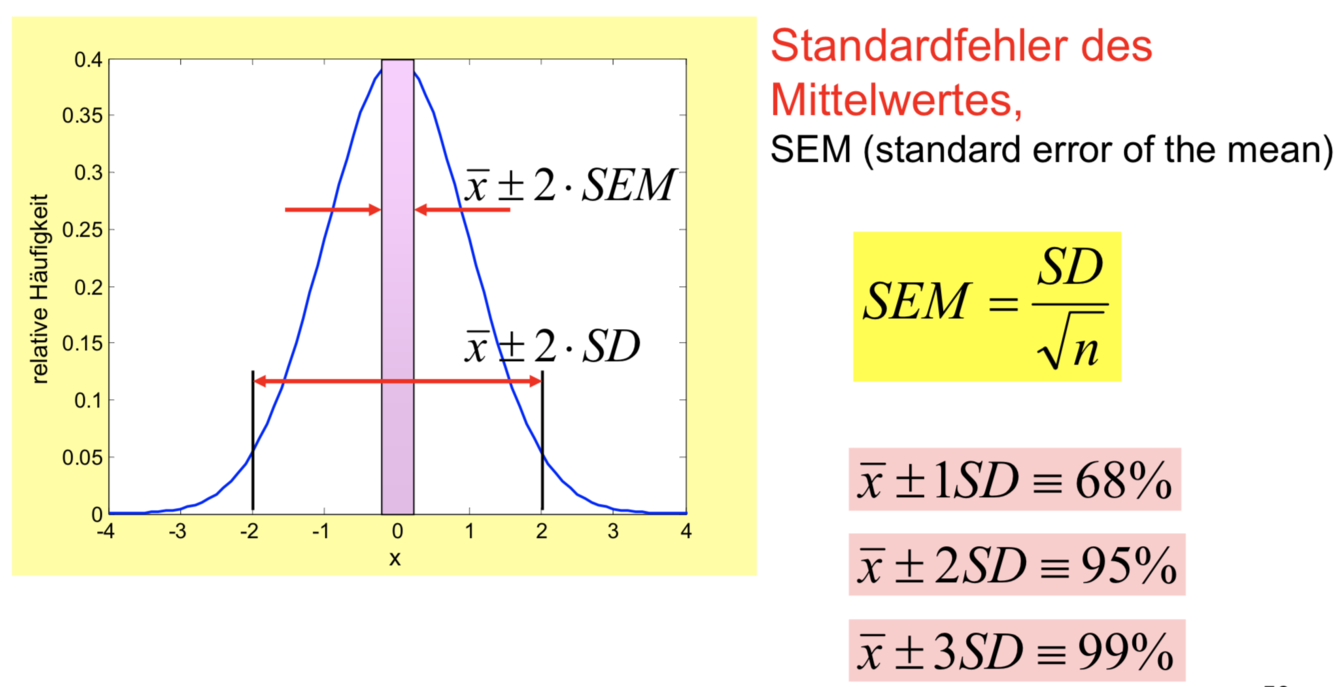
Standardfehler des Mittelwertes,
SEM (standard error of the mean)
Bei einer Normalverteilung der Daten kann man an Hand der SD abschätzen, wie viele Daten innerhalb einer bestimmten Streubreite enthalten sind. So kann man bspw. davon ausgehen, dass bei einer Streubreite von 2SD in diesem Bereich 95% aller Daten enthalten sind, man also fast alle Daten erfasst. Bei anderen Verteilungen sieht es natürlich anders aus und muss im konkreten Fall untersucht werden.
Ein wichtiges Maß ist der Standardfehler des MW, der SEM (Siehe Konfidenzintervall). Diese Beziehung ergibt sich aus dem Fakt, dass bei der arithmetischen Mittelung von stochastischen Daten die Varianz des Mittels um den Faktor n reduziert wird, wobei n die Anzahl der gemittelten Daten angibt.
Manchmal wird in Studien oder Publikationen gerade der SEM angegeben, was im Grunde nicht falsch ist. Allerdings kann man oft unterstellen, dass dem statistisch nicht kundigen Leser eine viel höhere Genauigkeit vorgetäuscht werden soll, als sie tatsächlich war und zumindest mit der gleichzeitigen Angabe der SD auch dokumentiert werden müsste. Bspw. wird bei 100 Versuchen der SEM 10mal geringer ausfallen als die SD. Das kann im Zweifelsfall zu falsch begründeten Entscheidungen führen, z.B. beim Kauf eines bestimmten Medizingerätes aus einem größeren Angebot von Produkten.
- Deskriptive Biostatistik
Streumaße
Das p-Quantil gibt an, bis zum welchen Wert von x (von links, von niedrigeren Werten her gesehen) der Anteil p von allen Daten liegt. Damit ist das Quantil zwar ein Streumaß, gleichzeitig aber auch eine Information über die Lage der empirischen Verteilung (siehe Box-Whisker-Plot). Quantile sind an sich Rangparameter, da sie Information über die Anteile (Häufung) der Daten liefern und nicht über die Ausprägung der Merkmale selbst.
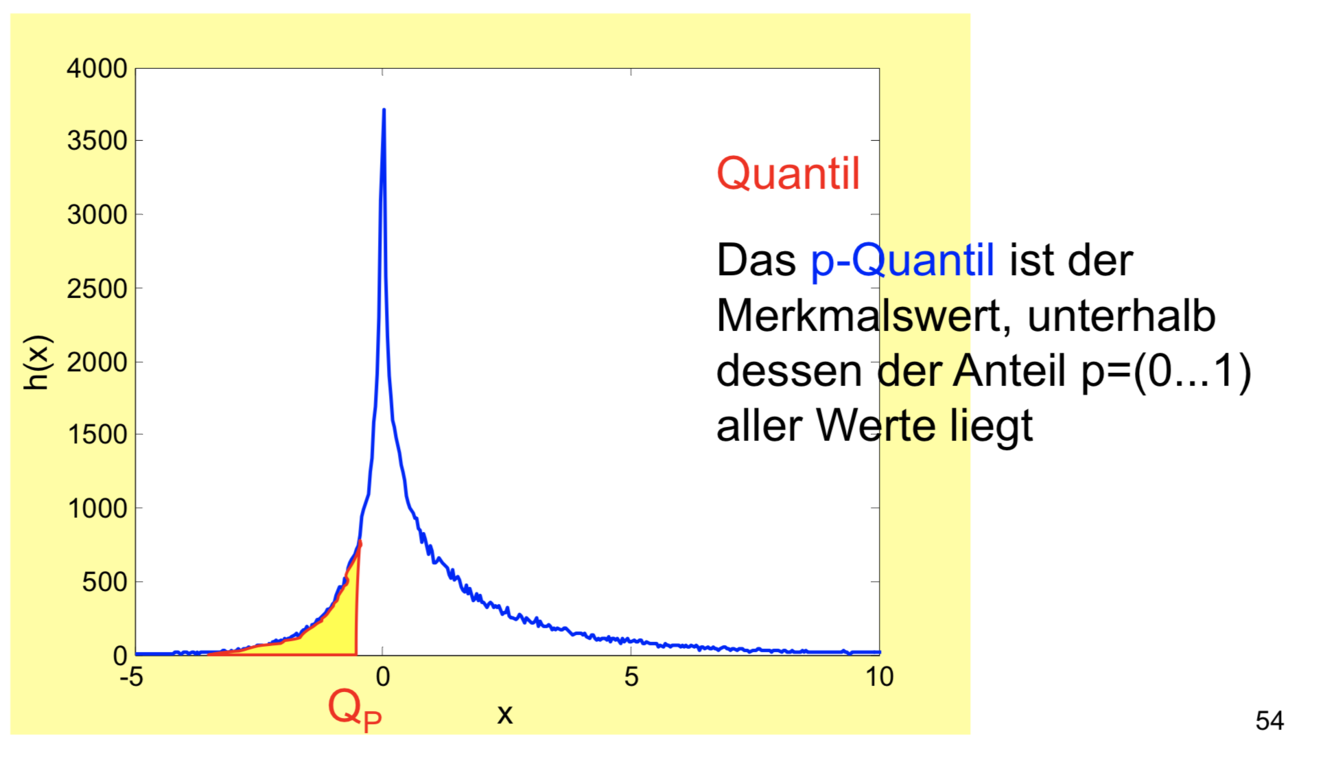
- Deskriptive Biostatistik
Streumaße
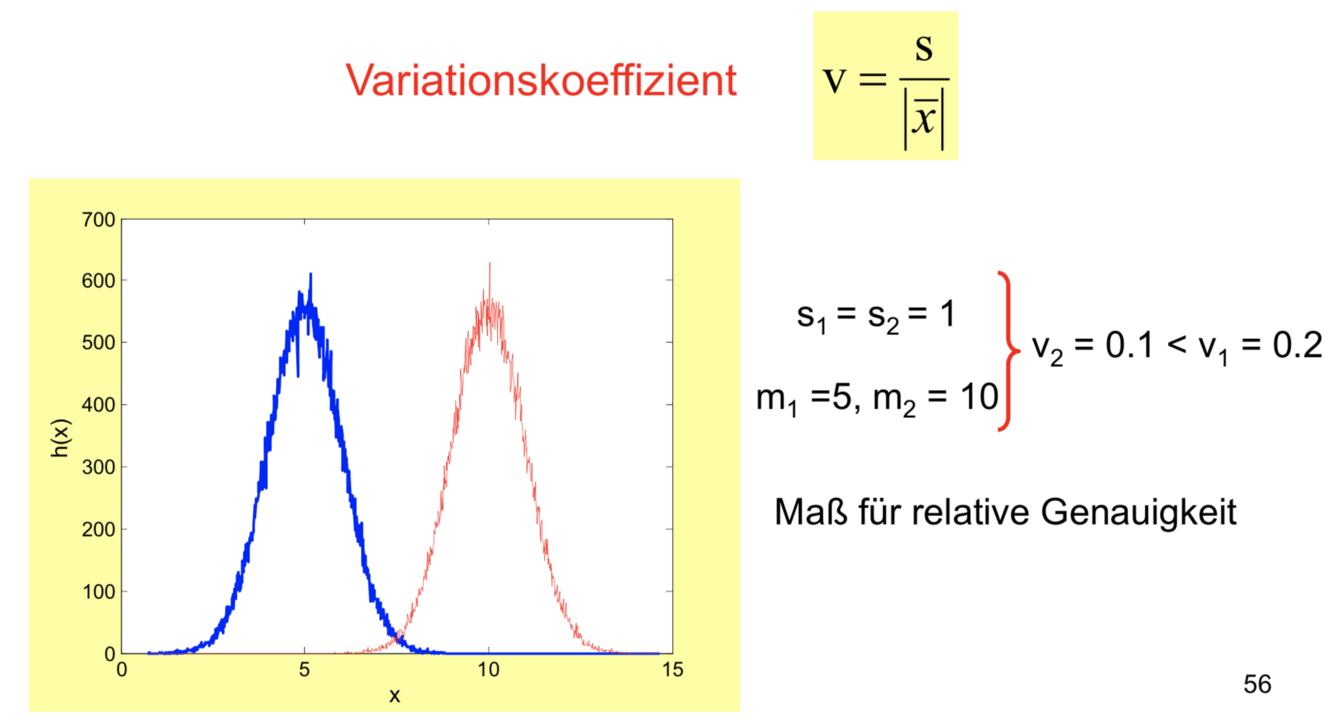
Variationskoeffizient
Der Variationskoeffizient kann in der Datenerfassung durch Messung als Genauigkeit interpretiert werden. Allerdings muss man bei der Interpretation der Ergebnisse unterscheiden, wodurch die Streuung entstanden ist. D.h. welchen Anteil der Messfehler und welchen die natürlich vorhandene Variabilität einnimmt. Im Normalfall wird gefordert, dass die Messgenauigkeit um mindestens eine Größenordnung höher liegt, als die natürliche Schwankung der Messdaten. Vor allem aber in der Medizin ist diese Forderung oft nicht erfüllbar.
Die Standardabweichung einer Stichprobe wird durch den jeweiligen Mittelwert dividiert. Der Korrelationskoeffizient drückt daher das relative Verhältnis der Streuung zum Mittelwert aus. Der Variationskoeffizient besitzt keine Einheit.
- Deskriptive Biostatistik
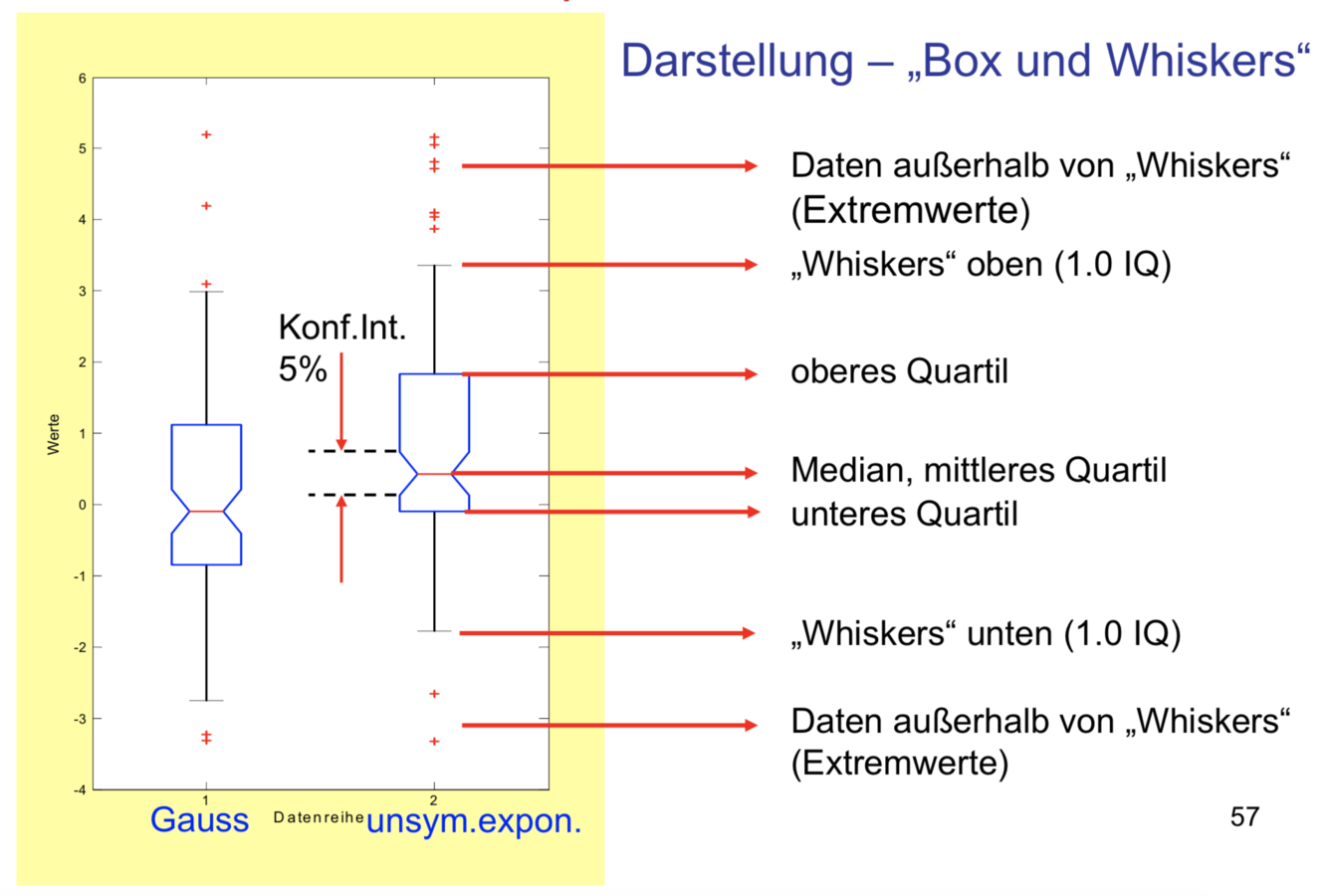
Darstellung – „Box und Whiskers“
Der Boxplot ist eine sehr anschauliche Darstellung der Daten mit wenigen Parametern, die die Verteilung der Daten repräsentiert. Aus den beiden Stichproben lassen sich die wichtigsten Eigenschaften ermitteln. Währen die linke Verteilung symmetrisch ist (Gaussdaten), zeigt die rechte Spalte eine deutliche Unsymmetrie. Das untere Quartil ist vom Median deutlich weniger entfernt als das obere Quartil, was auf eine Häufung der Daten im unteren Teil hindeutet. Der Einschnitt (notch) beim Median zeigt den Bereich des Medians an, in dem der Median mit 95%-Sicherheit tatsächlich liegt (sog. Konfidenzintervall, siehe Analytische Statistik). Man kann auf diese Weise mit einem Blick erkennen, ob die beiden Mediane voneinander signifikant unterschiedlich sind. Wenn sich nämlich die Einschnitte nicht überdecken, so kann man von unterschiedlichen Medianen ausgehen. In dieser Darstellung wäre die Entscheidung allerdings grenzwertig.
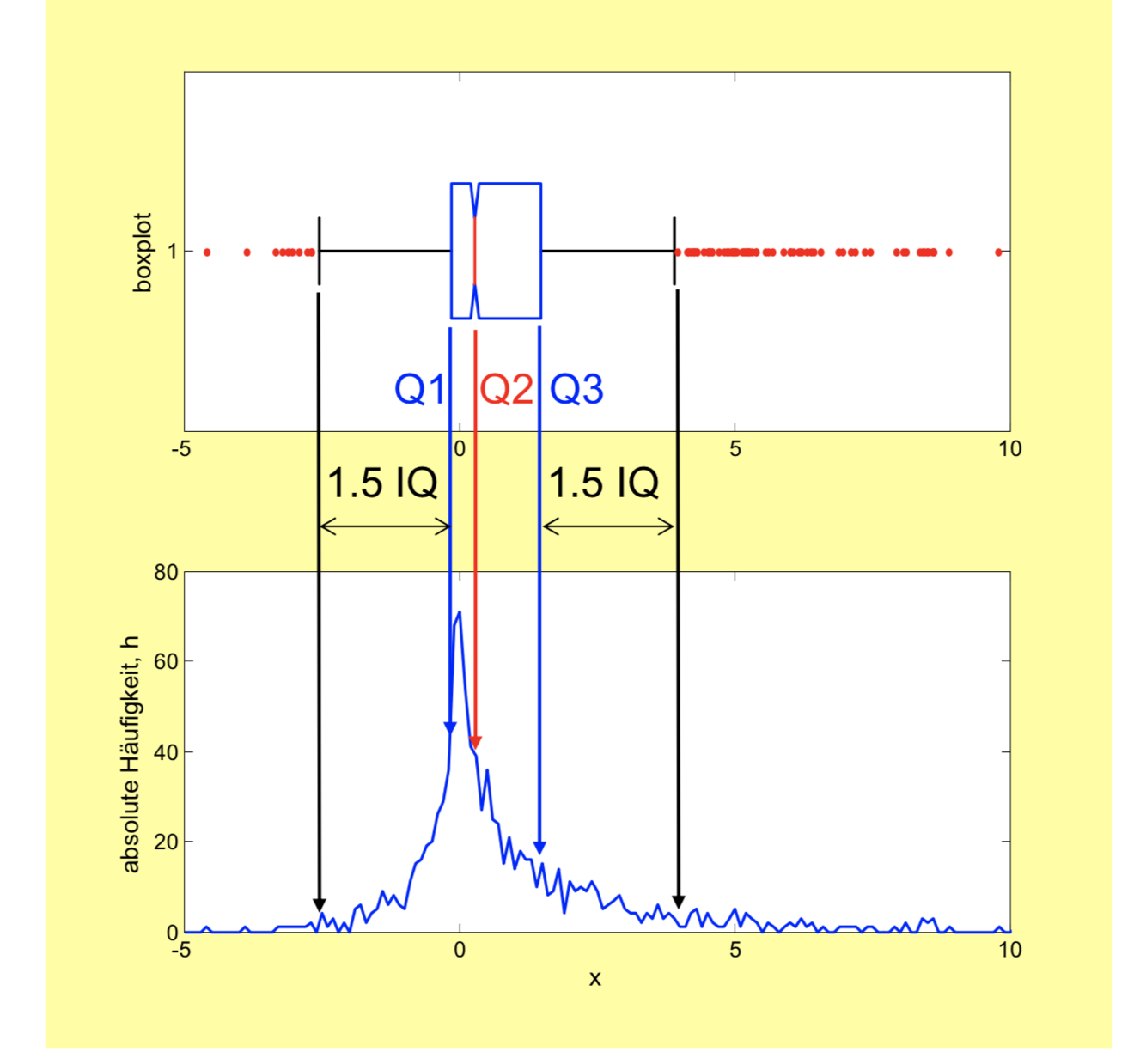
Diese Grafik soll veranschaulichen, wie effektiv die Darstellung an Hand des Boxplots ist. Während man für die empirische Verteilung (unten) u.U. sehr viele Parameter braucht (hier 100 Klassen), so reichen für den Boxplot fünf Parameter, die Quartile. Allerdings gibt der Boxplot keine Auskunft über den Modus und den Mittelwert.
IQ:Interquartile = Q3-Q1
- Deskriptive Biostatistik
Formmaße
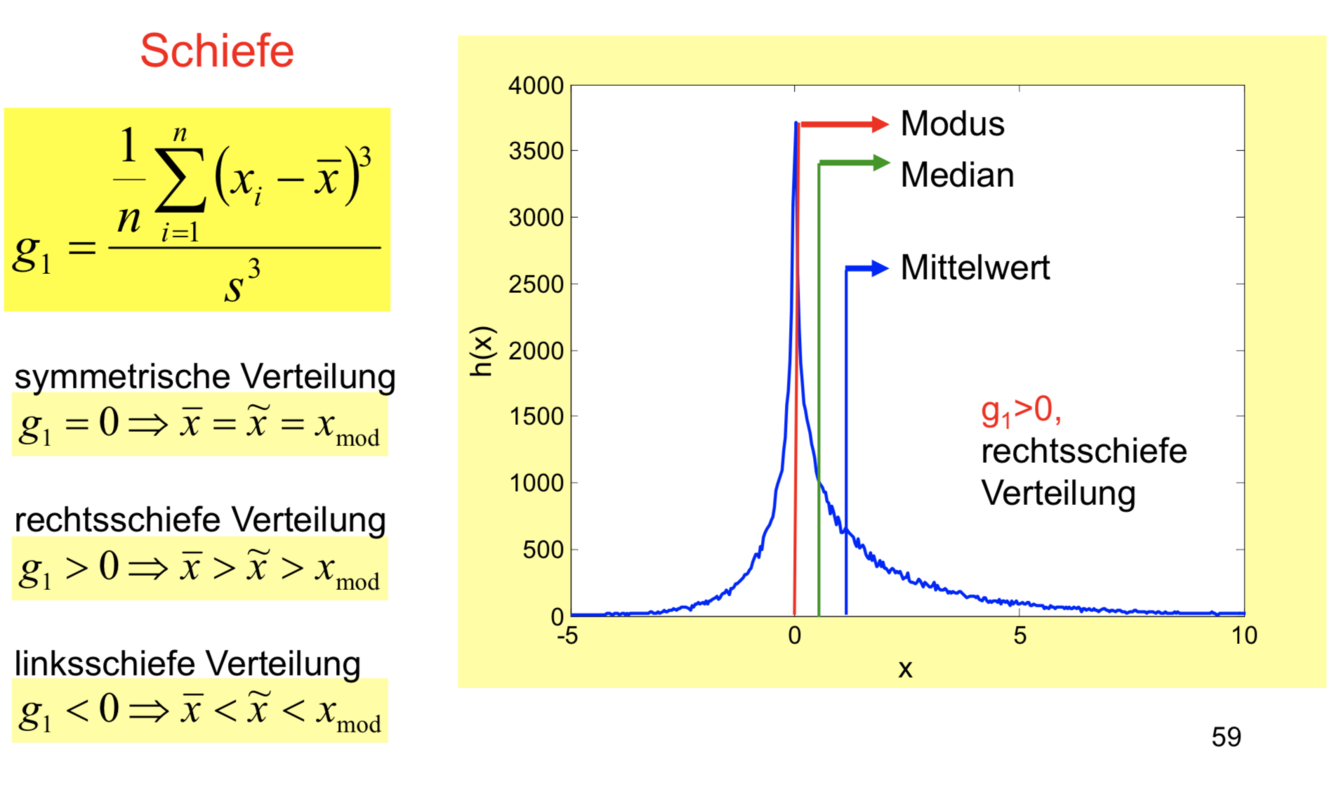
Schiefe
Rechtsschiefe Verteilungen sind typisch für Medizin und Biologie.
- Deskriptive Biostatistik
Formmaße
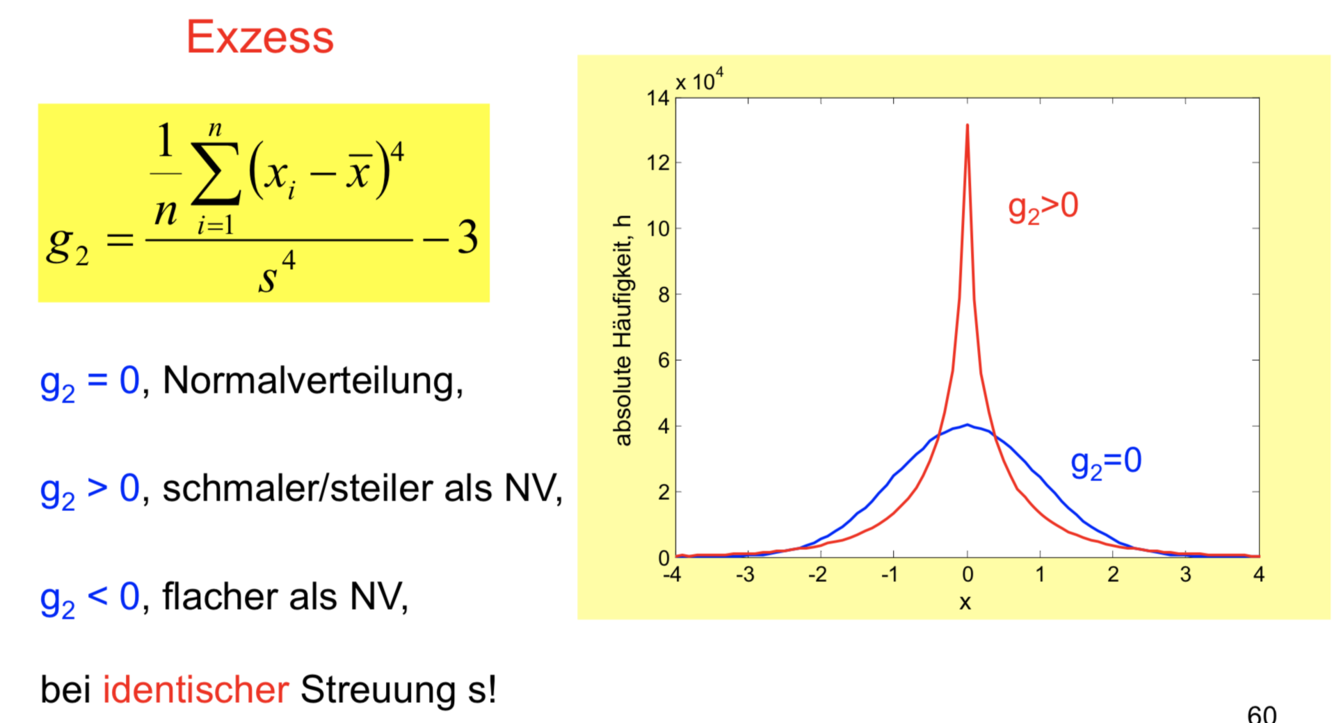
Exzeß
- Deskriptive Biostatistik

In der Statistik werden diese Funktionen vollständig als Wahrscheinlichkeitsverteilungsfunktion bzw. Wahrscheinlichkeitsdichtefunktion bezeichnet. Da es hier später gleichermaßen um Häufigkeiten wie auch Wahrscheinlichkeiten gehen wird, werden die Bezeichnungen Verteilung und Verteilungsdichte verwendet.
Für kontinuierliche Verteilungen gilt, dass die Verteilungsdichte sich aus der ersten Ableitung der Verteilung nach der Zufallsvariablen ergibt. Bei diskreten ZV werden die entsprechenden diskreten Zuwächse herangezogen.
- Deskriptive Biostatistik
Der zentrale Grenzwertsatz

- Deskriptive Biostatistik
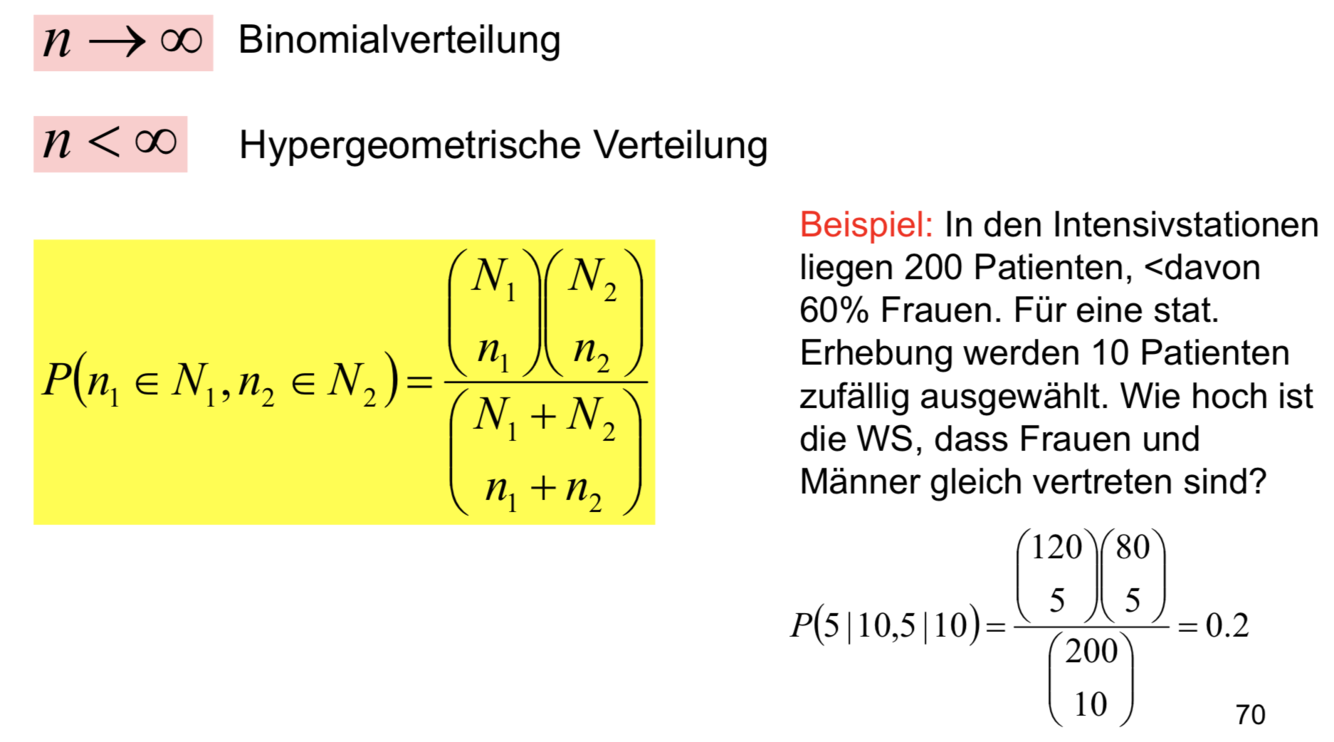
Hypergeometrische Verteilung
超几何分布是统计学上一种离散概率分布。它描述了从有限N个物件(其中包含M个指定种类的物件)中抽出n个物件,成功抽出该指定种类的物件的次数(不放回)。
- Deskriptive Biostatistik
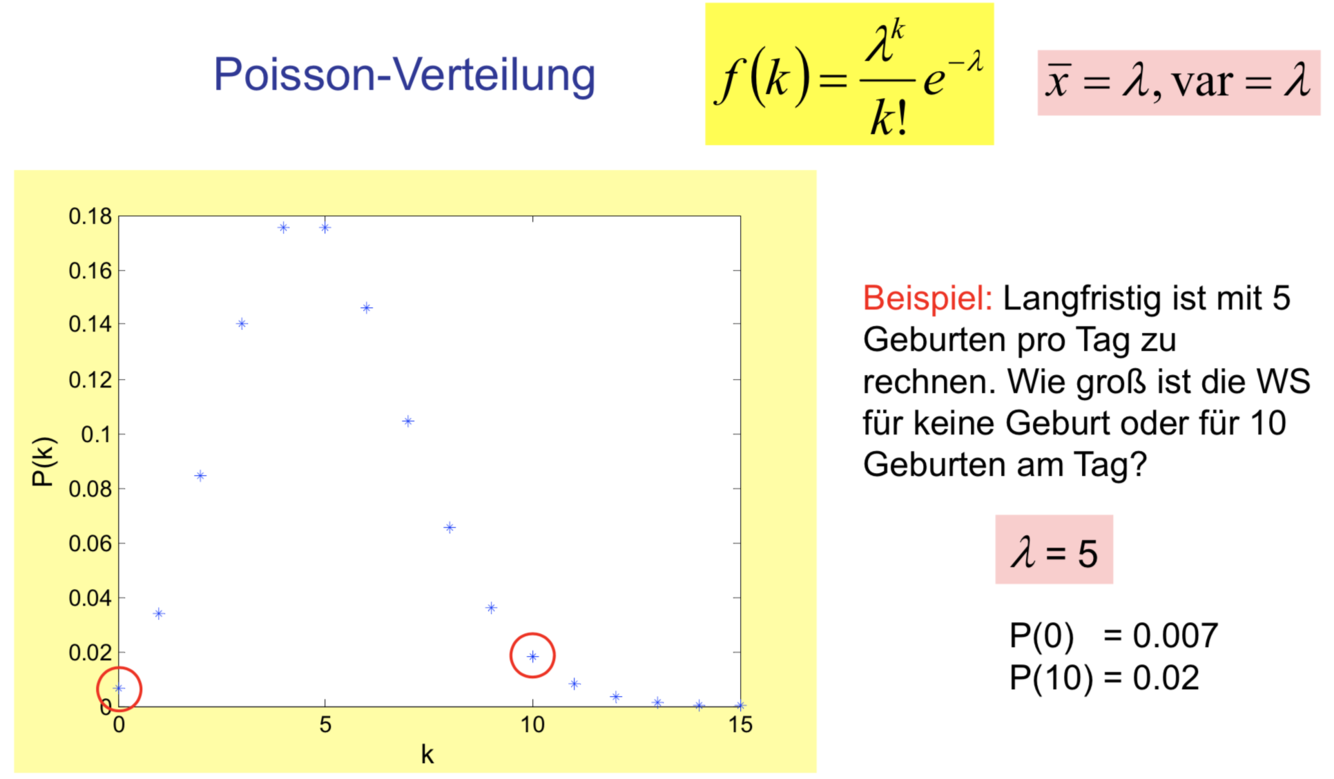
Poisson-Verteilung
Poisson-Verteilung ist typisch für diskrete Zufallsvariable mit geringer WS des Auftretens. Für sehr hohe n setzt man für die beiden Parameter n und p in der Binomialverteilung durch deren Produkt lambda = n*p ein, so erhält man die Poisson-V.
- Deskriptive Biostatistik
Lineare Regression von y auf x
- Die einfachste Approximation eines statistischen Zusammenhangs ist die lineare Regression. Sie ist gleichzeitig die Lösung für die Methode der kleinsten Fehlerquadrate, ohne dass das die Methode hier explizit angewandt wurde.
- byx ist der Regressionskoeffizient der Regression von y auf x. Dieser ist anders als bxy, also in der Regression von x auf y,
- syx ist die Kovarianz, sie ist symmetrisch, Details später,
- sxx ist die Varianz,
- ayx ist der nullte Polynomterm

- Deskriptive Biostatistik
Bivariate Datenbeschreibung
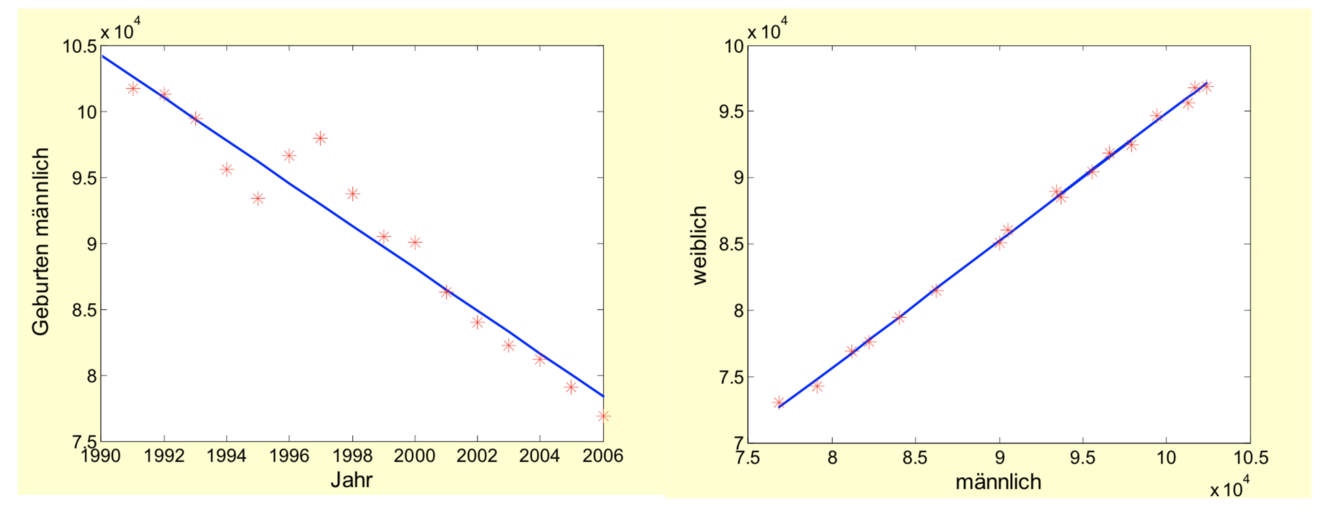
Die Regression kann grundsätzlich zwischen jedem Paar von Variablen angewandt werden, so auch auf den Zeitverlauf. Zeitliche Verläufe sind allerdings Gegenstand von Zeitreihenanalysen bzw. Analyse der stochastischen Prozesse. Daher wird im weiteren auf dieses Thema verzichtet, siehe BSV2.
Die Geburtenzahlen in NRW seit 1990 sind als Zusammenhang zwischen männlichen und weiblichen Neugeborenen dargestellt, also ohne einen Zeitbezug. Man kann auf den ersten Blick erkennen, dass der Zusammenhang sehr stark ist, also wenig Schwankungen zwischen den Geburtenzahlen auftreten.
- Deskriptive Biostatistik
Bivariate Datenbeschreibung
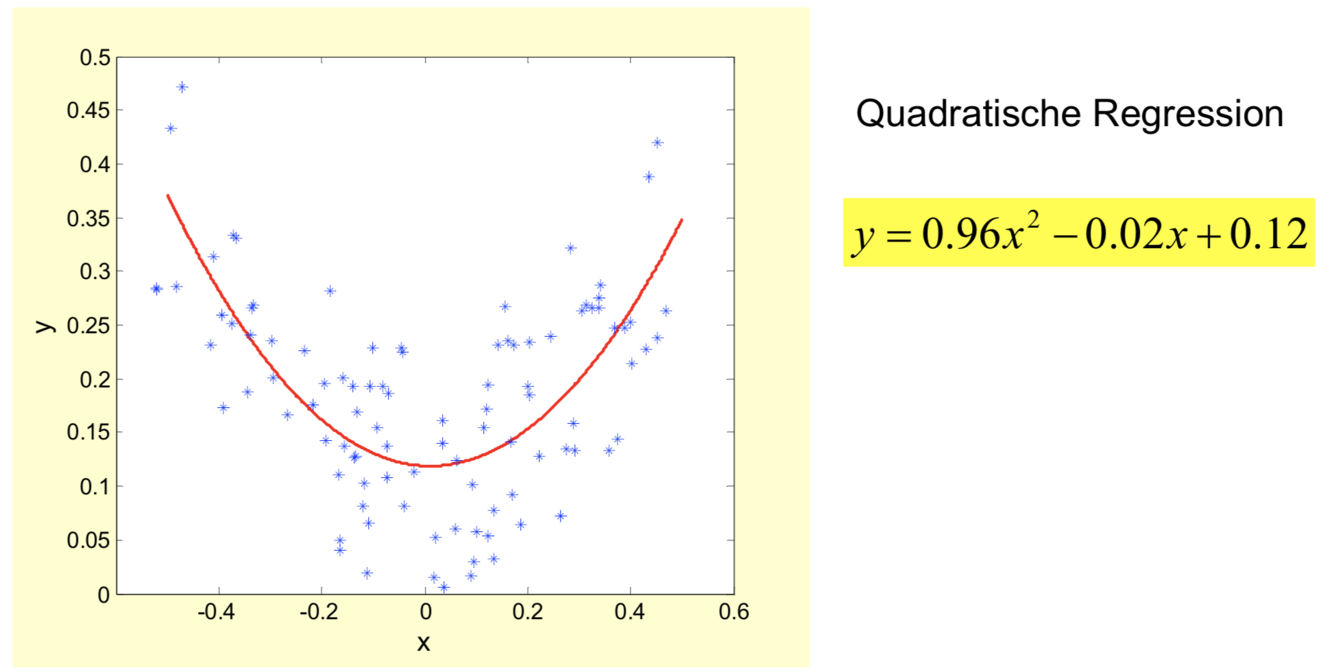
Natürlich sind auch Zufallsvariable voneinander nichtlinear abhängig, so wie exakt ermittelbare physikalische und technische Größen. Die Schwierigkeit besteht in der Bestimmung des Grades der Nichlinearität, die umso größer wird, je höher die Streuung der Daten. In diesem Beispiel wäre auch eine andere gerade Nichtlinearität denkbar, z.B. die vierte Ordnung, oder der Cosinus. Ich habe die zweite Ordnung für das Fitting gewählt, weil ich natürlich wußte, wie ich die Daten generiert habe. Die Wahl der Fittingfunktion ist nicht trivial, da sie in der weiteren Analyse auf die Modellierung von System- und/oder Signalparametern Einfluß haben kann.
- Deskriptive Biostatistik
Bivariate Datenbeschreibung
Korrelationskoeffizient nach Pearson

Der KK nach Pearson gibt AUSSCHLIESSLICH über den linearen Zusammenhang Auskunft. Das heißt, dass jedes Wertepaar mit dem selben Faktor und einer gewissen Streuung beschreibbar ist. Jeder weitere Zusammenhang ist theoretisch nicht nachweisebar. Praktisch jedoch hängt Vieles von den konreten Daten ab, wie später gezeigt wird. Selbst bei hoch nichtlinearen Zusammenhängen können nachweisbare KK heraus kommen, die theoretisch nicht vorhanden sind. Man kann diesen Fakt in etwa so interpretieren, dass der KK nach Pearson einen Zusammenhang umso deutlicher zeigt, je näher er an die lineare Abhängigkeit heran kommt.
Ein wesentlicher Nachteil des Pearson-KK ist, dass er exakt nur ausgewertet werden kann, wenn die untersuchten ZG normalverteilt sind. Und das ist in der praktischen Analyse sehr selten der Fall bzw. man kann über die Verteilung keine Aussage treffen.
Für die praktische Analyse gelten ganz grob die aufgeführten Faustregeln.
- Deskriptive Biostatistik
Bivariate Datenbeschreibung
Rang-Korrelationskoeffizient nach Spearman

Wie wir schon beim Median, Quantilen und getrimmeten Mittelwerten beobachten konnten, bringen Rangfolgen eine gewisse Robustheit in die Analyse. Und obwohl – oder gerade weil - sie selbst nichtlineare Operatoren sind, können sie einen nichtlinearen Zusammenhang besser identifizieren. Ausserdem sind sie robust gegen die Forderung nach der Normalverteilung der Daten.
- Deskriptive Biostatistik
Interpretation der Korrelation
- Formale Korelation
- Selektionskorrelation
- Korrelation durch Ausreißer
- Inhomogenitätskorrelation
- Gemeinsamkeitskorrelation
- Formale Korelation
- Selektionskorrelation
- Korrelation durch Ausreißer
- Inhomogenitätskorrelation
- Gemeinsamkeitskorrelation
- Deskriptive Biostatistik
Korrelationsanalyse - Fehlinterpretationen
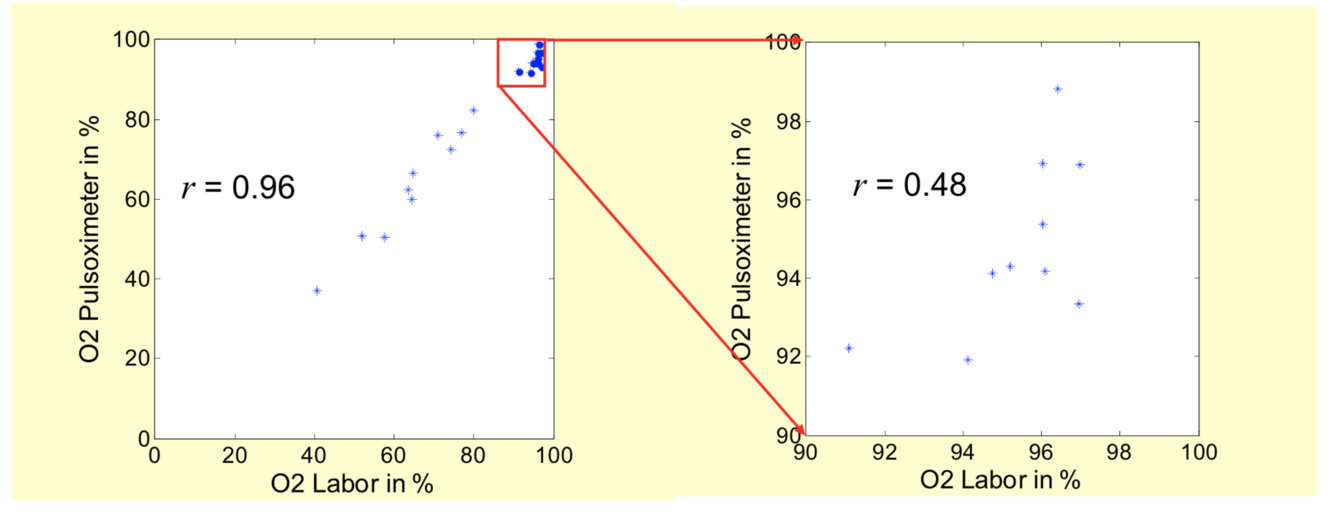
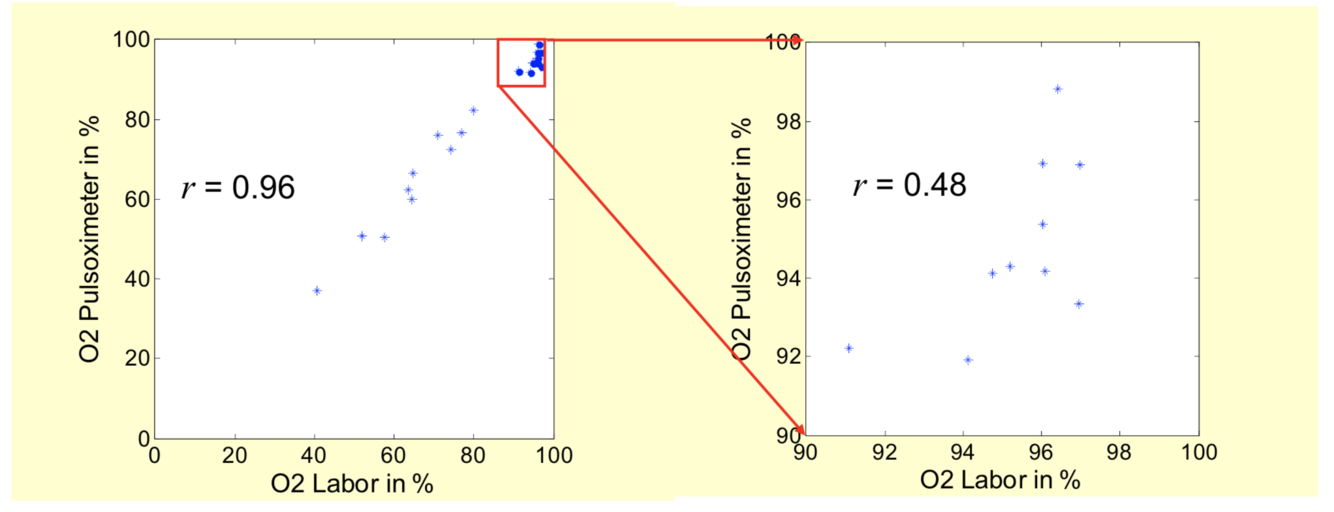
- unrealistisch hoher KK wegen großer Spannweite des Messbereichs. Innerhalb des Nutzbereichs deutlich geringer
- unrealistisch hoher KK bei systematischen Fehlern: beim hohen CO-Anteil (> 1%) ändert sich die Anzeige im Pulsoximeter nicht, d.h. r << 0.48 bzw. r << 0.96
- Analytische Biostatistik
Schätzverfahren
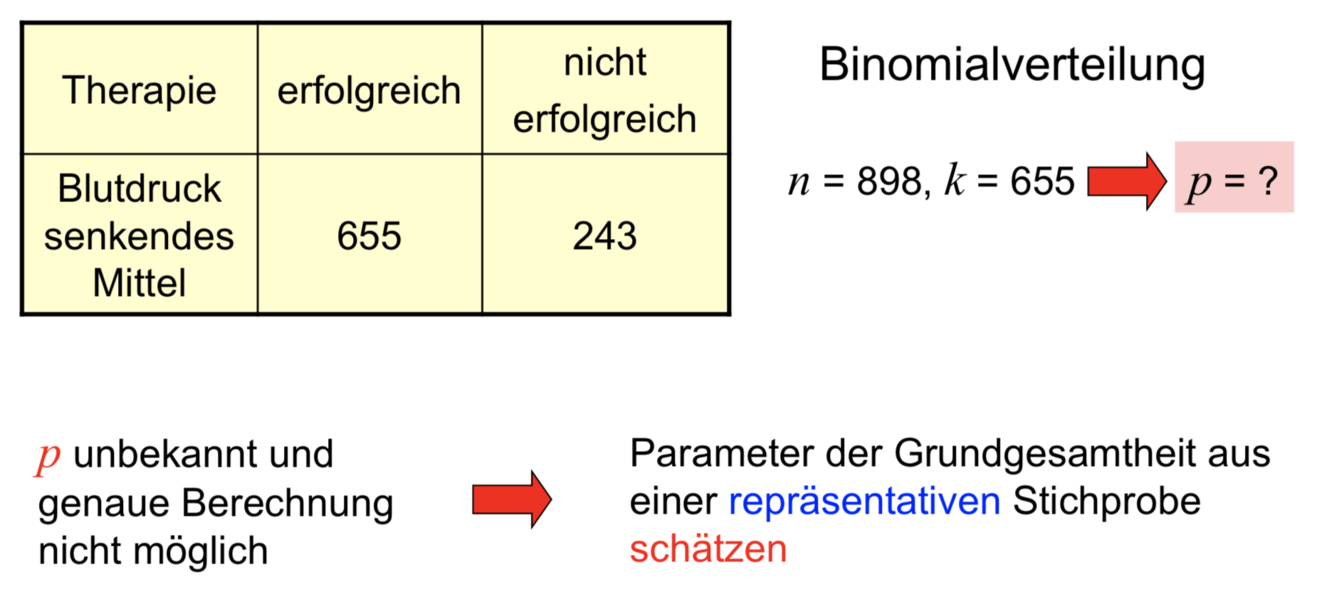
In diesem Beispiel handelt es sich offensichtlich um eine Binomialverteilung, da die ZG nur zwei Werte annehmen kann (0 – nicht erfolgreich, 1 – erfolgreich). Die theoretische Erfolgswahrscheinlichkeit ist aber nicht bekannt, sonst müssten wir die klinische Studie nicht durchführen. Sie ist auch nicht genau berechenbar, denn dazu bräuchten wir sehr viele Einzelversuche (n > 10e6), die unter identischen Voraussetzungen durchzuführen wären. Und das ist praktisch nicht realisierbar. Daher werden wir versuchen, den Erfolg an Hand einer Stichprobe (SP) aus der Grundgesamtheit (GG) zu schätzen. Damit die SP die gesuchten Parameter gut abbildet, muss sie repräsentativ sein. Praktisch heißt das, aller für die Studie relevanten Merkmale müssen in der SP anteilig so vertreten sein, wie in der GG. Und dies ist eines der größten Probleme bei der praktischen analytischen Statistik. Wenn man genau wüsste, wie die einzelnen Merkmale in der GG verteilt sind, müsste man sie nicht untersuchen. Der Ausweg besteht darin, dass man die SP nach Möglichkeit sehr groß wählt in der Hoffnung, dass die Merkmale damit rein statistisch der Originalverteilung der GG entsprechen. Aus der SP werden nach bestimmten Schätzverfahren die gesuchten Parameter der GG geschätzt. Bsp.: In einer Studie zu Blutdruck senkenden Mitteln dürfte man nicht Patienten einschließen, deren BD am oberen Ende des möglichen Bereiches liegt. Da bei diesen physiologisch ohnehin nur noch eine Absenkung möglich ist, würden sie fälschlicherweise einen Therapieerfolg demonstrieren.
- Analytische Biostatistik
Schätzverfahren

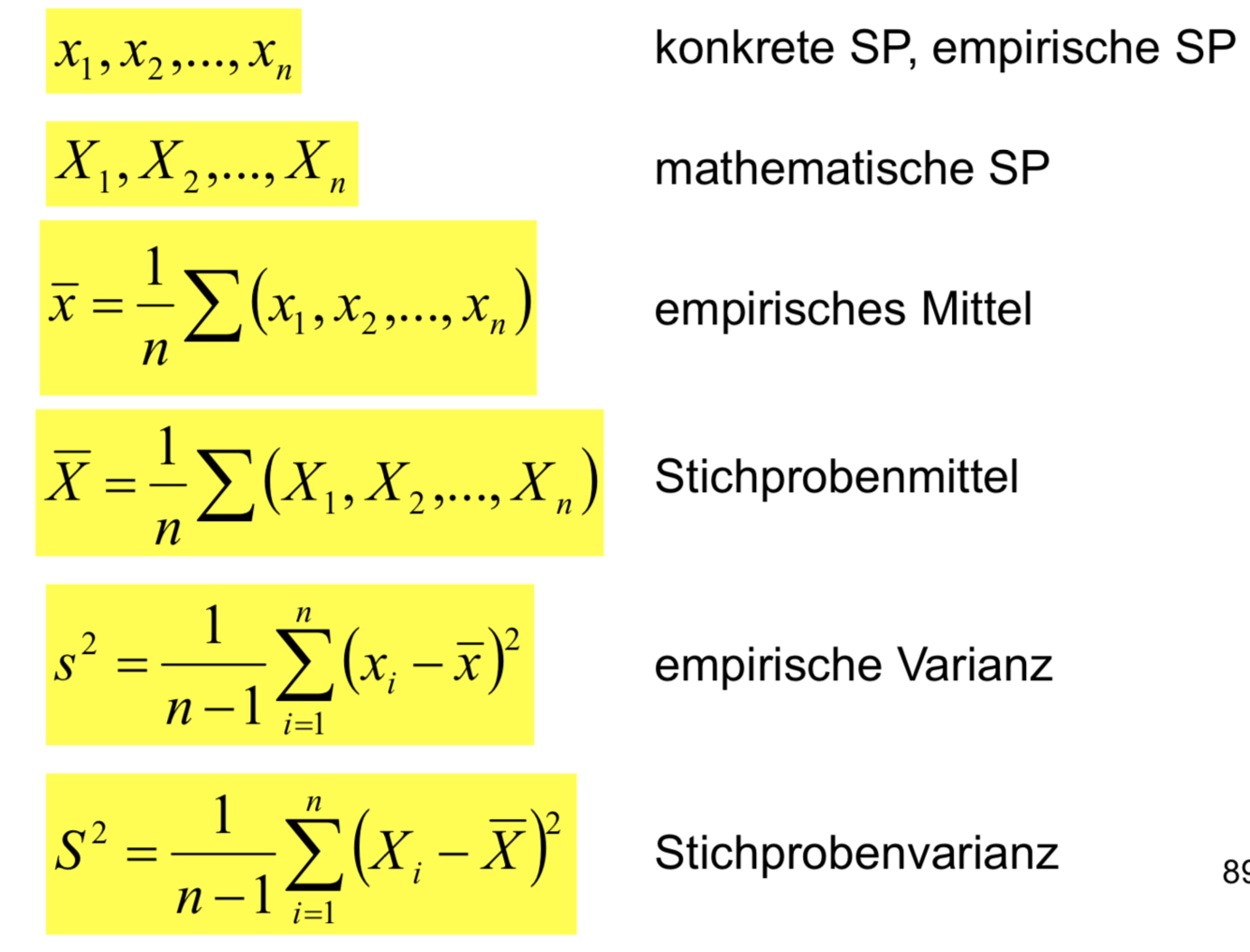
Die Verwendung der Schreibweise ist die gleiche, wie in der deskriptiven Statistik: mit kleinen Buchstaben werden konkrete (gemessene, ermittelte) Werte, mit großen Buchstaben die statistischen Größen (Variable, Maße).
- Analytische Biostatistik
Schätzverfahren

- Wird der gesuchte Parameter der GG durch einen einzigen Wert geschätzt, so sprechen wir von einer Punktschätzung.
- Die Vorschrift, nach der dieser Wert berechnet wird, heißt Schätzfunktion oder Schätzer. In diesem Beispiel der arithmetische Mittelwert.
- Die Werte, die der Schätzer in der SP annimmt, heißen Schätzwerte.
- Erwartungswerte werden in der Regel über arithmetische Mittelwerte der SP berechnet.






















































































