k-NN process overview

Goal
given a set of labeled items, automatically label a new item
Idea
Consider most similar other items (defined in terms of their attributes), look at their labels and give the unassigned item the majority votes. Ties broken randomly.
To automate knn, what two decisions need to be made
- How to define similarity?
- How many should vote? (what is k?)
Euclidean distance
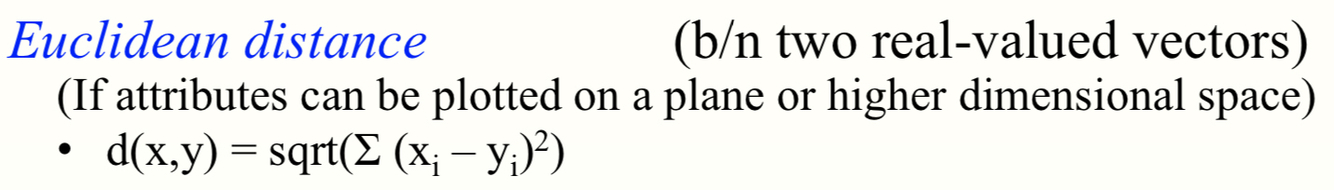
Cosine similarity
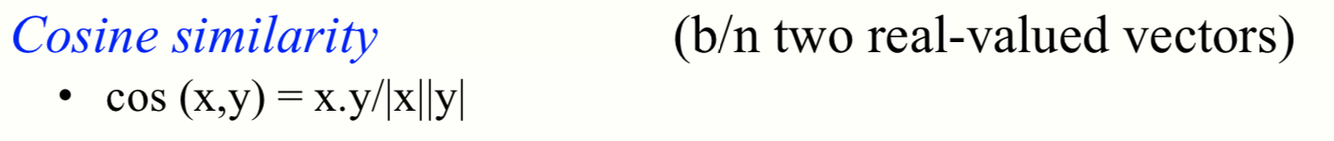
Jaccard distance

Hamming distance

Manhatan distance
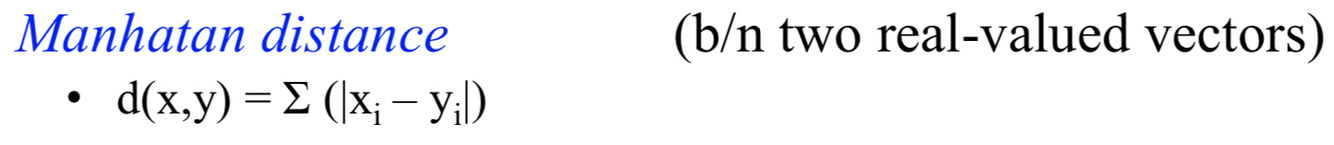
Regarding distance metrics…what if attributes are a mixture of kinds of data?
Define your own custom designed metric
synonymous terms
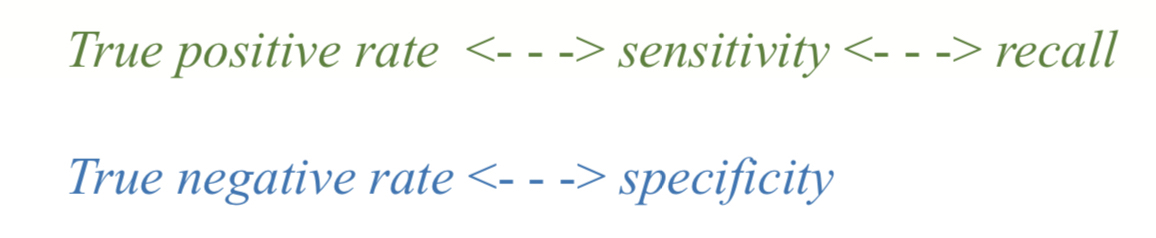
Evaluation metrics
- Accuracy
- Precision
- Recall
- F-score
Evaluation Metric : Accuracy
number of correct labels / (total number of labels)
Evaluation Metric : Precision
number of true positives /
(number of true positives + number of false positives)
Evaluation Metric : Recall
Number of true positives /
(number of true positives + number of false negatives)
Evaluation Metric : F-score
Harmonic mean of precision and recall
(2 × precision × recall) / (precision + recall)
Evaluation Metric : Misclassification rate
1-accurary
Choosing k
- Need to understand data well to get a good guess
- Then try a few different k’s and see how evaluation changes. Pick the k that optimizes the chosen evaluation metric
- In binary classification, pick k to be an odd number
Modeling assumptions in K-NN

Scaling
Standardize the data so that all variables are given a mean of zero and a standard deviation of one.
In R, this can be achieved using the scale() function
