What’s the difference between pmf and pdf?
pmf applies to discrete.
pdf applies to continuous
What are two advantages of MAP?
- It is easy to incorporate our prior assumptions about the value of q by adjusting the ratio of gamma1 to gamma0.
- It is easy to express our degree of certainty about our prior knowledge, by adjusting the total volume of imaginary coin flips. For example, if we are highly certain of our prior belief that q = 0.7, then we might use priors of gamma1 = 700 and gamma0 = 300 instead of gamma1 = 7 and gamma0 = 3.
What’s one key idea about the behavior of MAP?
As the volume of actual observed data grows toward infinity, the influence of our imaginary data goes to zero
What’s the equation of map?
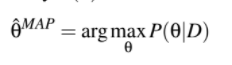
What’s the equation of MLE?
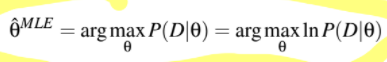
What’s a key difference between MAP and MLE?
- MAP assumes background knowledge is available, whereas MLE does not.
For MLE and MAP, what happens as the size of the dataset grows?
The MLE estimate and MAP estimate converge toward each other and toward the correct estimate
Between MLE and MAP, which should perform better when there’s little data available?
MAP because the influence of our assumptions from previous knowledge has a larger impact when the data set is small
What’s the definition of MLE?

Define prior
The prior, of an uncertain quantity is the probability distribution that would express one’s beliefs about this quantity before some evidence is taken into account.
What is iid?
independent, identically distributed
It’s a Combination of two assumptions:
- the outcomes of different trials are independent
- identically distributed - the same distribution governs each trial
What is likelihood?
L(q) = P(D|theta)
The probability of a data set given the probability parameters (theta)
What’s the equation for log likelihood?
l(theta) = ln (P(D|theta))
Can express P(D|theta) as a product of the individual probabilities, because P(D|theta) is a probability distribution
Why is there a log in the log likelihood?
Having a log there just makes it mathematically easier to maximize the likelihood
What is MLE maximizing? (simple expression)
P(D|theta)
What is MAP maximizing? (simple expression) (2)
P(theta|D) or P(D|theta)P(theta)
What is a bernoulli random variable?
- We have exactly one trial only
- we define “success” as a 1 and “failure” as a 0.
What is the conjugate prior for estimating
the parameter theta of a Bernoulli distribution?
Beta distribution
What do we know about the Dirichlet distribution?
The Dirichlet distribution is a generalization of the Beta distribution,
What’s the Principle of MLE? (in words)

How would you describe the inductive bias of MLE?
MLE tries to allocate as much probability mass as possible to the things we have observed… …at the expense of the things we have not observed
What allows us to use the product of probabilities in the log likelihood equation
the independence assumption
How do you calculate the closed-form MLE? (5 steps)

What’s log(A*B*C)?
log(A) + log(B)+log(C)








