What is Big Data
- information that cannot be processed using traditional methods due to:
- volume - extemely large datasets,
- variety - of sources
- velocity - often need to be real-time
Often
- raw – unclear how to obtain value
- Unstructured / Semi structured
Today companies have the ability to store any data they generate, but don’t know what to do with it.
more data = more processing
key drivers of Big Data
This trend started when
- enterprises created more data from their operations
- Web and social media content explosion
- IoT
- networked devices
3 reasons for the expontential data growth
Instrumentation
- more sensors
- more storage
Interconnection
- more things are interconnected
Intelligence
- computers have become cheap
- software has become powerful
- Systems on a Chip (SoC) are dense, fast, cheap
3 Big Data Characteristics
- Volume
- Variety
- Velocity
- (Veracity - trustworthness)
- (Value)
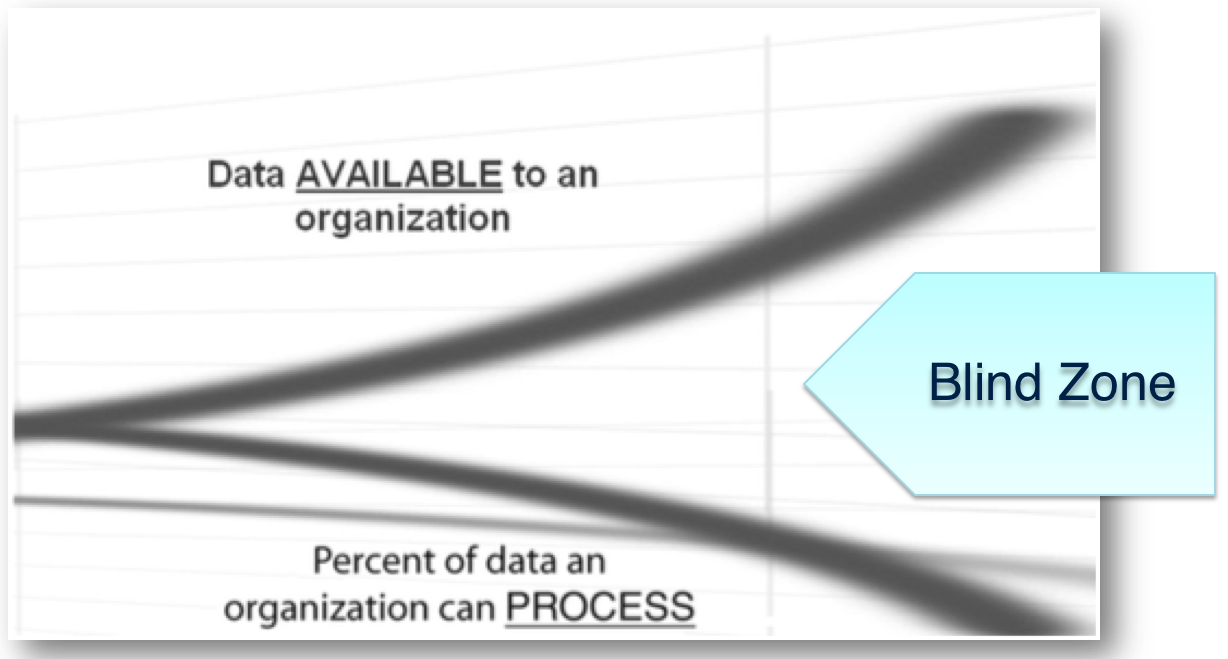
What is the Blind Zone?
We create more data than we can process.
Blind Zone = WE don’t know
- Couldbe a great opportunity
- Could be nothing
- But we don’t know and we don’t have the capacity to find out.
Can data warehouses handle Big Data and why?
- They’re great with structured data, ideally relational
- Struggle with Big Data due to variety
How much data an organisation creates, is cleansed, transformed and loaded into Data Warehouse?
Only 20% of data that could be used.
- albeit the very important 20%
80% of data is Raw, Unstructured or Semi Structured.
3 categories of data based on its form in the primary source
- Structured: transactional data from enterprise applications
- Semi-structured: machine data from the IOT
- Unstructured: text, audio and video from social media and Web applications
Relational databases only work well with structured data.
How to handle unstructured data?
NoSQL databases (“Not only” SQL databases)
NoSQL Databases Attributes
- Significant installed base of systems, particularly websites, using a NoSQL database
- Supports distributed, scalable, and real-time data updates
- Schema-free design that provides flexibility to start loading data and then changing it later
- Provides BASE rather than ACID support.
- Basically available: high availability of 24/7 (often demanded for most transactional systems), is relaxed
- Soft state: database may be inconsistent at any point in time
- Eventually consistent
NoSQL database falls into several technology architecture categories:
- Key-Value
- Column-Family
- Document
- Graph
Relational Databases Attributes
- Large installed base of applications, often running key business processes within an enterprise
- Large pool of experience people with skills such as DBA, application developer, architect, and business analyst
- Increasing scalability and capability due to advances in relational technology and underlying infrastructure
- Large pool of BI, data integration, and related tools that leverage the technology
- Requires a schema with tables, columns, and other entities to load and query database
- For transactional data it provides ACID support to guarantee transactional integrity and reliability.
- Atomic: Entire transaction succeeds or ii is rolled back
- Consistent: A transaction needs to be in a consistent state to be completed
- Isolated: Transactions are independent of each other
- Durable: Transactions persist after they are completed
define data velocity
How fast data is generated, flows, is stored, retrieved and analysed.
key characteristics of stream analytics + 2 use cases
- Data has a short shelf life
- Spot trend, opportunity, or problem in microseconds
- algorithmic traders
- fraud detection
Basically, what is required to make Big Data valuable?
Need to be able to process a massive volume of disparate types of data and analyse it to produce insight in a time frame driven by the business need.
- The algorithms and models haven’t changed.
- We are still doing correlation and link analysis and prediction.
- It’s just that the volume of data we run the models against have become much larger.
- Machine learning has an increasing part to play
Are DW trusted? Need?
Businesses need trust.
- Data in a data warehouse is trusted.
- It goes through a rigorous process of cleansing, formatting, enrichment, meta data attachment etc.
- It’s high quality
- Quality is expensive
- Data in a DW is high value.
Need
- Government regulations require high quality data.
- CEO CFO of companies publically traded on US based stock exchanges must certify accuracy of their financial statements. This also applies to their non-US operations.
Characteristics of Hadoop
- a platform for storing, managing, and analysing Big Data
- open source
- basis for many Data Lakes
- the platform that kicked off the ubiquity of big data analytics
- lets you store all the data in its native format
- makes data valuable through massive parallel processing (MPP)
- run on a cluster of machines
- work is distributed; crunch more data by using more machines, more processing power.
HDFS - Hadoop Distributed File System
A distributed, scalable, and portable file system written in Java for the Hadoop framework.
Its data is divided into blocks, and copies of these blocks are stored on multiple servers across the Hadoop cluster.
Think of a file that contains the phone numbers for everyone in the United States; the people with a last name starting with A might be stored on server 1, B on server 2, and so on. Hadoop pieces together the phonebook across its cluster.
The example below shows such replication on both the same rack and other racks (double protection).
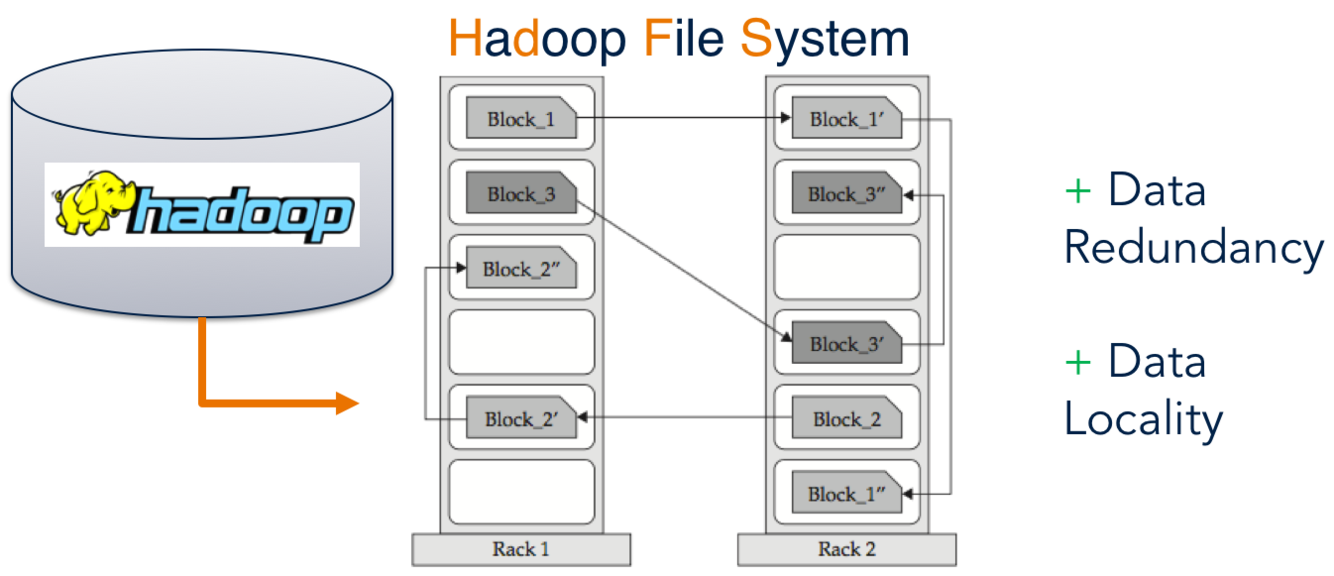
3 benefits of Hadoop’s file redundancy
Reduncacy achieves availability even as components fail.
- redundancy can be increased or decreased on a per-file basis or for a whole environment
Redundancy increases scalability
- redundancy allows the Hadoop cluster to break work up into smaller chunks and run those jobs on all the servers in the cluster which increases scalability.
Rundandacy makes data local
- data locality is critical when working with large data sets
MapReduce programming model
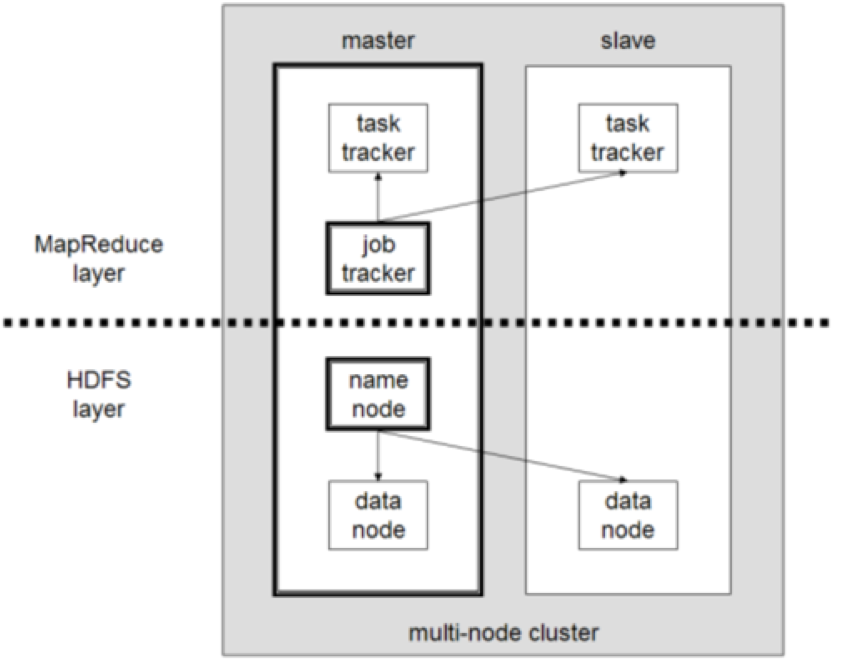
- components of a HDFS cluster
*
Components of a HDFS cluster
- namenode
- datanode
- job tracker
- task tracker
A HDFS cluster has two types of nodes (i.e. servers) operating in a master-slave pattern (master-worker). A cluster has one namenode, as master node and and a number of worker datanodes.
namenode - manages the filesystem namespace
- maintains the filesystem tree and the metadata for all the files and directories in the tree
- information is stored persistently on the local disk of the namenode in the form of two files:
- the namespace image
- the edit log
- the namenode also knows the datanodes on which all the blocks for a given file are located.
namenode essential for the filesystem to function
- acts as a Single Point of Failure (SPOF)
- backup namenodes
Datanodes hold the filesystem data in the form of blocks.
- store and retrieve blocks when they are told to (by clients or thenamenode)
- report back periodically to the namenode with lists of blocks that they are storing
MapReduce Framework follows master-worker architecture.
- the master is a single JobTracker
- the worker notes are TaskTrackers
The JobTracker handles the runtime scheduling of MapReduce jobs and maintains information on each TaskTrackers’s load and available resources.
Each job is broken down into Map tasks, based on the number of data blocks that require processing, and Reduce tasks. The Jobtracker assigns tasks to TaskTrackers based on locality and load balancing.
It achieves locality by matching a TaskTracker to Map tasks that process data local to it, preferably on the same node or, failing that, on the same rack.
It load-balances by assuring that all availableTaskTrackers are assigned tasks. TaskTrackers regularly update the JobTracker with their status through heartbeat messages.
master node contains
- Namenode
- JobTracker
- database connector
worker nodes contain
- datanodes
- distributed database blocks
- TaskTracker
Performing a Hadoop ‘Job’
outline + example
- Split data and distribute across cluster
- Split task across cluster
- MapReduce
- Perform Map Task, write output to temp storage
- Perform reduce task against temp storage
- Return output to central node.
- Job is split and pushed down to the data
- Count number of unique family names in UCL
- Input student name file - Split data and distribute across cluster.
- Send task to each node
- MapReduce on each node
- Sort alphabetically, write sorted list to temp store
- Count unique against temp storage
- Return output to central node
- Central Node collates data and returns final answer
3 phases of MapReduce
MapReduce is a programming model that is used as part of a framework, such as Hadoop, based on key-value pairs.
It forces a file to undergo three stages:
1. Map: the task is distributed among the computers in the cluster and processes the inputs; produce key-value pairs
- the application operates on each record in the input separately
2. Shuffle: collects and sorts the keys (keys being chosen by the user) and distributed to different machines for the reduce phase. Every record for a given key will then go to the same reducer.
3. Reduce: takes the results from the map phase and combine them to get the wanted result;
- the application is presented each key, together with all of the records containing that key (done in parallel). After processing each group, the reducer can write its output.
Programming in Hadoop
PIG
- Java like language specifically for Hadoop
- The language in which Hadoop jobs are written
HIVE
- SQL like language specifically for Hadoop
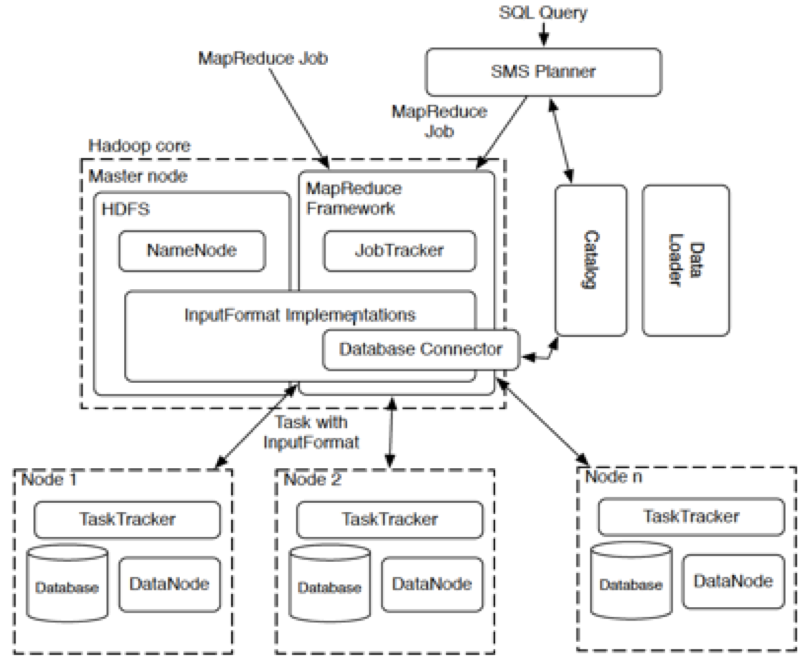
Summary of HadoopDB Architecture
An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads
Apache Spark
- Extends the MapReduce model to support more types of computations
- Stream processing
- Interactive queries
- Works well with Hadoop
- and Amazon S3, Cassandra, Hive, Hbase, etc.
- and Python, Scala
Apache Spark provides programmers with an application programming interface centered on a data structure called the resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines, that is maintained in a fault-tolerant way.It was developed in response to limitations in the MapReduce cluster computing paradigm, which forces a particular linear dataflow structure on distributed programs: MapReduce programs read input data from disk, map a function across the data, reduce the results of the map, and store reduction results on disk. Spark’s RDDs function as a working set for distributed programs that offers a (deliberately) restricted form of distributed shared memory.
The availability of RDDs facilitates the implementation of both iterative algorithms, that visit their dataset multiple times in a loop, and interactive/exploratory data analysis, i.e., the repeated database-style querying of data. The latency of such applications may be reduced by several orders of magnitude compared to a MapReduce implementation (as was common in Apache Hadoop stacks). Among the class of iterative algorithms are the training algorithms for machine learning systems, which formed the initial impetus for developing Apache Spark
Apache Spark requires a cluster manager and a distributed storage system. For cluster management, Spark supports standalone (native Spark cluster), Hadoop YARN, or Apache Mesos. For distributed storage, Spark can interface with a wide variety, including Hadoop Distributed File System (HDFS), MapR File System (MapR-FS),Cassandra,OpenStack Swift, Amazon S3, Kudu, or a custom solution can be implemented. Spark also supports a pseudo-distributed local mode, usually used only for development or testing purposes, where distributed storage is not required and the local file system can be used instead; in such a scenario, Spark is run on a single machine with one executor per CPU core.
