La qualité de l’inférence statistique dépend
directement de la qualité des […]
La qualité de l’inférence statistique dépend
directement de la qualité des données
Quelles sont les 6 étapes de l’inférence statistique?
- Choix de l’échantillon et des instruments
- Collecte et saisie de données
- Transformation des données
- Exploration des données
- Analyse descriptive des données
- Analyse inférentielle des données
Quelles sont les différentes étapes de saisie directe des données pour éviter les erreur? (3)
- Saisie simple: Quand on fait passer des questionnaires papier, puis on entre les données à l’ordinateur
- Saisie vérifiée (validation des champs): Dès qu’il va y avoir une réponse qui est invalide selon la programmation de la saisie qui sera capturé (ex: Rentre dans un programme spécifique pour une échelle de 1 à 4 et on entre 5 par erreur)
- Double saisie: Deux personnes indépendantes vont entrer les réponses (saisir les mêmes questionnaires). Donc s’il y a des différences, il y a des erreurs qui seront à vérifier. Avec ça, on a une très bonne base de donnée
**Les méthodes de saisie informatisée, où l’acquisition de données est réalisée en temps réel et/ou par le participant, sont idéales pour réduire les problèmes de saisie.
Comment fait-on pour vérifier la qualité de l’ensemble de nos variables, en fonction du type de variable (continue, nominale)?
- Variable continue
- Moyenne et écart-type
- Étendue des scores
- Variable dichotomique ou nominale
- Fréquence de chaque valeur
Quels sont les inconvénients qu’entraînent les données manquantes? (3)
- Affecte les paramètres estimés (biais)
- Affecte la puissance statistique des tests
- Affecte la généralisation des résultats (validité externe)
** Le patron des données manquantes est plus important que la quantité de données manquantes
Quels sont les trois patrons de données manquantes?
- MCAR (missing completely at random)
- La probabilité d’avoir une donnée manquante est parfaitement imprévisible. Elle n’est pas reliée aux données observées ou manquantes.
- Conséquence: L’analyse sur les sujets disponibles est valide, même si moins puissante
- Ex: Une partie des questionnaires complétés a été perdue par la poste
- MAR (missing at random)
- La probabilité d’avoir une donnée manquante est reliée aux variables déjà observées dans la base de données. Elle n’est pas reliée à la valeur de la donnée manquante.
- Conséquence: Si on tient compte des variables (prédicteurs; ex: sexe) reliées à la probabilité des données manquantes dans le modèle statistique, l’analyse sur les sujets disponibles est valide (on diminue le biais des DM dans nos résultats).
- Ex: Les sujets de sexe masculin répondent moins fréquemment à une question sur l’humeur dépressive
- MNAR (Missing not at random)
- La probabilité d’avoir une donnée manquante est reliée aux variables NON observées dans la base de données. Elle est reliée à la valeur de la donnée manquante.
- Conséquence: On doit tenter d’identifier des variables qui permettront indirectement de mesurer la probabilité d’avoir une donnée manquante puis faire les analyses selon le patron MAR. Sinon, analyses de sensibilité (+++ complexe).
- Ex: Les sujets avec un revenu élevé ont tendance à ne pas répondre à la question sur le revenu
Quelles sont les quatre méthodes de gestion des données manquantes?
- Ne rien faire et utiliser des modèles robustes
- Certains modèles statistiques (p.ex., modèles mixtes) tiennent compte des DM en assumant qu’elles sont MCAR/MAR
- Par contre, il va y avoir un baisse de puissance (d’où l’utilisation de modèles robustes)
- Retrait des observations incomplètes
- Retirer les observations incomplètes pour obtenir une base de données de sujets complets
- Imputation des données manquante
- Calculer une valeur estimée qui va remplacer la valeur manquante, pour obtenir une base de données de sujets complets
- Pondération des observations
- Donner davantage de poids aux observations complètes pour compenser l’absence des participants similaires
Dans la méthode de retrait des observations avec des données manquantes, quels sont les deux types de retrait possibles?
- Retrait total des observations incomplètes (listwise deletion)
- Se fait par défaut dans SPSS, SAS, etc.
- Retrait des observations par analyse (pairwise deletion)
- Disponible dans tous les logiciels. Méthode qui amène des biais et donc rarement utilisée.
** À utiliser dans un contexte où les données manquantes sont complètement aléatoire (MCAR)
Dans la méthode d’imputation des données manquantes, quels sont les cinq types d’imputation possibles?
- Imputation par moyenne de la variable
- Réduit la variance/covariance des données
- Imputation par régression
- Augmente la covariance des données
- Imputation selon le plus proche voisin (hot-deck)
- Projection de la dernière donnée disponible (last observation carried forward) (longitudinal)
- Problème: Assume qu’il n’y a aucun changement dans le temps
- Expectation-maximization (EM) ou imputation multiple
Dans la méthode d’imputation des données manquantes, expliquer l’imputation par moyenne de la variable ainsi que son effet sur les résultats.
Il y a deux moyennes (variable choisi de tous les participants; moyenne du participant (en fonction de son pattern de réponse)) que l’on peut mettre à la place de la donnée manquante:
- Mettre la moyenne du groupe (tous les participants) pour la variable choisie: Pas très personnalisé, réduit donc la variabilité
- Mettre la moyenne du participant: Réduit la variance des données puis le fait de toujours mettre l’imputation de la moyenne, ça va réduire l’écart-type et donc la corrélation ainsi que la covariance.
Dans la méthode d’imputation des données manquantes, expliquer l’imputation selon le plus proche voisin ainsi que son effet sur les résultats.
On voit que dans la base de donnée, souvent les participants vont avoir à peu près les mêmes caractéristiques que la personne avec les données manquantes. Donc on peut utiliser ces réponses pour compléter les données manquantes de l’autre.
-> Le problème est que si on veut un profil similaire, en pratique ça demande beaucoup d’analyse pour trouver le profil le plus similaire!
Dans la méthode d’imputation des données manquantes, expliquer les étapes de l’imputation multiple.
- Calculer la matrice de VC(variance-covariance) sur les données disponibles
- Prédire les données manquantes à l’aide d’une régression multiple et imputer ces valeurs dans la base de données
- Recalculer la matrice de VC et la comparer avec celle de départ. Si différences, refaire l’étape 2 jusqu’à ce que les deux matrices soient similaires
** Ici, on s’assure que il n’y a pas trop de différence entre ma matrice de départ et celle corrigée pour les données manquantes. On fait ces calculs à répétition.
*** Cette méthode est rendu un standard dans l’imputation. Par contre, en science sociale il y a encore une résistance face au imputation (on manipule les données puisque ce ne sont pas “des vrais données”).
Dans la méthode de pondération des observations pour la gestion des données manquantes, comment calcule-t-on le poids attribué aux données disponibles
Ex: On a trois groupes. G1 tout le monde répond 1, G2 tout le monde répond 2, G3 tout le monde répond 3. X sont les données manquantes.
- On va voir quelle est la probabilité d’avoir répondu: G1 1/3, G2 3/3, G3 2/3.
- Le poids c’est l’inverse de la probabilité (donc chaque personne va représenter tant de personnes): G1 1 personne représente 3, G2 1 personne représente 1 personne, G3 1 personne représente 1 1/2 personne.
- On doit ensuite redistribuer les résultats avec le poid qui les représente si on divise le poid total avec le nombre de réponse attendu.
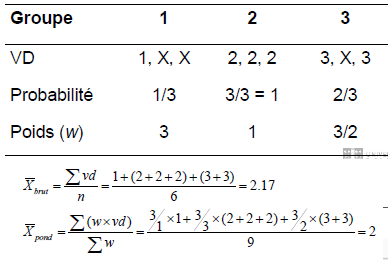
Qu’est-ce qu’une donnée extrême?
Une donnée rare selon la distribution statistique, qui est éloignée de la valeur des autres données du même échantillon.
* Une donnée extrême peut être observée sur une variable nominale ou continue
D’où provient les données extrêmes?
- Erreur dans la saisie des données (données abhérrantes)
- Erreur dans les codes de données manquantes
- Appartient à une autre population
- Donnée valide mais peu probable
* Une donnée extrême continue (multivariée) provenant d’une variable continue provient de la combinaison improbable de plusieurs variables
Comment identifie-t-on les données extrêmes univariée en fonction du type de variable (nominal, continue)?
- Variable nominale
- Valeur dont la fréquence est faible (<10%)
- Variable continue
- Valeur située à >3.29 écarts-type de la moyenne (p < .001, bilatéral)
- Notre point de référence est la moyenne sur la distribution noramle. Donc plus on est loin de la moyenne plus on de chance d’être une donnée extrême.
Quelles sont les deux caractéristiques d’une donnée extrême multivariée?
- L’effet de levier (leverage) : est-ce que la donnée est distante du reste des données?
- Mesurée par la distance de Mahalanobis
- La déviation (discrepancy) : est-ce que la donnée affecte peu ou beaucoup la relation entre les variables pour le reste des données?
** L’influence d’une donnée extrême est fonction du levier et de sa déviation
- Mesurée par la distance de Cook
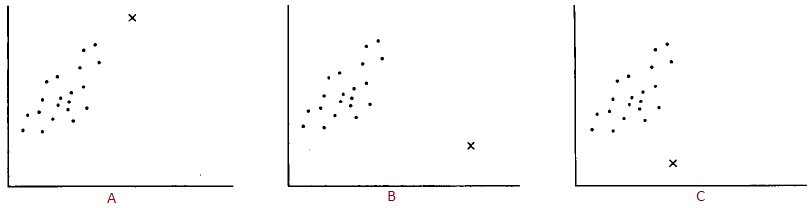
Décrivez la variable extrême de chaque tableau (a,b,c) en fonction du levier, de sa déviation ainsi que de son influence.
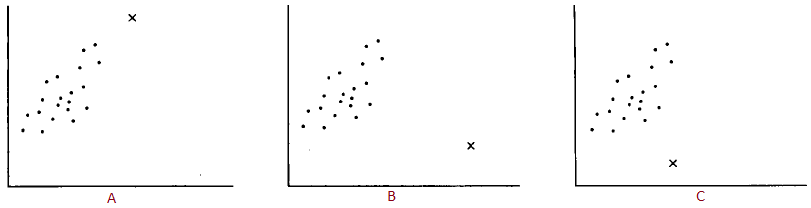
A) Le point x est en lien avec la relation, mais il est très loin. Il n’y aura pas trop d’impact sur la droite de régresssion. Donc elle a un fort levier (loin) mais peu déviante (suit la tendance) et donc peu d’influence sur la régression.
B) Le point x est très loin du jeu de donnée et complètement contre la tendance du jeu de donnée. Donc elle a un fort levier, une forte déviance et donc une forte influence sur la régression. La régression ne sera pas intéressante ni pour le jeu de donnée ni pour la variable extrême si elle prend en compte la variable extrême.
C) Le point x est proche du jeu de donnée mais contre sa tendance. Donc elle a un faible levier, une forte déviance et donc une influence modérée.
Pourquoi doit on s’occuper des données extrêmes?
- Une donnée extrême modifie la moyenne et la variance d’une variable (biais et efficacité de l’estimateur)
- Une donnée extrême augmente (ou diminue) la probabilité de faire une erreur de type I (alpha) ou II (beta)
Quelles sont les méthodes de gestion des données extrêmes? (4)
- Retirer les données extrêmes (qui deviennent manquantes)
- Avant c’était très utiliser, mais plus maintenant
- Transformer la variable affectée pour réduire l’influence des données extrêmes
- Estimer une valeur plus probable
- On va la remplacer par une autre valeur qui n’aura pas trop d’influence dans nos résultats (imputation plus raisonnable). Elle va être à la limite de notre critère de détection de valeur extrême
- Utiliser un test statistique peu ou non-sensible aux données extrêmes (i.e., statistique robuste ou non-paramétrique)
Quels sont les postulats de base de la plupart des méthodes d’analyses multivariées? (5)
- Indépendance des observations
- Normalité des distributions
- Multi-normalité des relations entre les variables
- Linéarité des relations entre les variables
- Homoscédasticité (homogénéité des variances)
Comment vérifie-t-on le postulat de normalité “univariée”?
Indices graphiques et statistiques
- Examiner histogramme ou normogramme (QQ-plot) (idée générale seulement)
- Calculer skewness (asymétrie) et kurtosis (aplatissement ou voussure)
- Test de normalité (p.ex., Shapiro-Wilk)
- Ho : la distribution respecte une courbe normale
- Critique: Trop sensible. Ce test va surdétecter la non normalité pour les gros échantillons
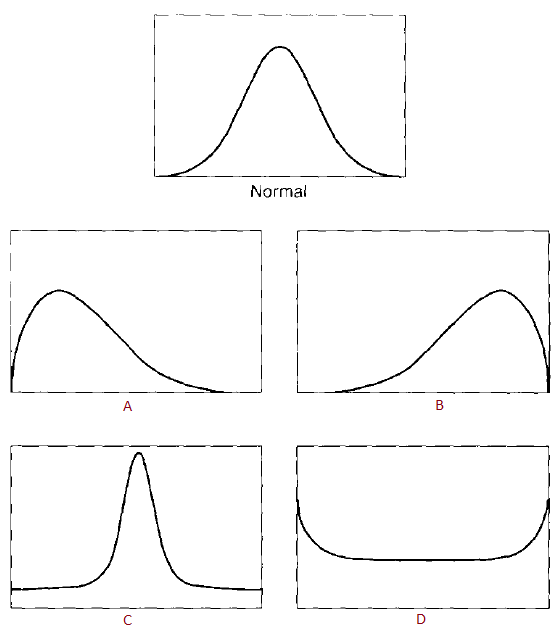
Que représente ces graphiques?
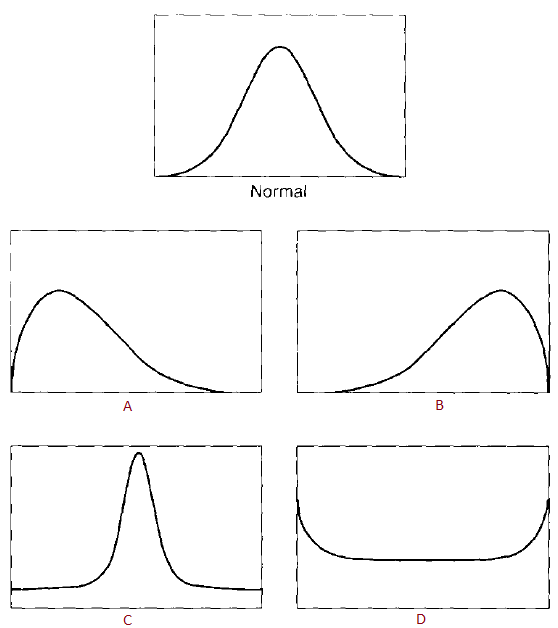
A) Asymétrie positive
B) Asymétrie négative
C) Voussure positive
D) Voussure nédative
À quoi faire-t-il faire attention lorsque l’on transforme une distribution problématique pour qu’elle représente davantage les caractéristiques d’une distribution normale?
- Les résultats (et donc les conclusions) sont tirées sur des données transformées
- Si la variable est mieux représentée par une autre loi (p.ex., loi de Poisson), la transformation est superflue et va même créer un problème!



