L’analyse de covariance (ANCOVA) est une extension de l’ANOVA qui permet d’ajuster la […] en fonction d’une ou plusieurs […]
L’analyse de covariance (ANCOVA) est une extension de l’ANOVA qui permet d’ajuster la VD en fonction d’une ou plusieurs covariables
Le test d’ANCOVA porte sur des […] ajustées (mi’) et l’ajustement se fait à l’aide d’une […] entre la covariable et la VD
Le test d’ANCOVA porte sur des moyennes ajustées (mi’ ; donc moyenne composée) et l’ajustement se fait à l’aide d’une régression entre la covariable et la VD
Hypothèses:
Ho: m1’ = m2’ = … = mk’
Ha: au moins une égalité est fausse
Quelle est la différence entre l’ANCOVA et la MANOVA?
ANOVA compare des moyennes.
MANOVA compare plus de deux moyennes
Dans l’ANCOVA, la variable dépendante doit être sur une échelle […], la variable indépendante doit être sur une échelle […] et la covariable doit être sur une échelle […]
Dans l’ANCOVA, la variable dépendante doit être sur une échelle continue, la variable indépendante doit être sur une échelle catégorielle (nominale) et la covariable doit être sur une échelle continue
VRAI ou FAUX
Presque tous les plans d’expériences peuvent être convertis en ANCOVA sans problème
VRAI
L’ANOVA est basé sur trois sommes de carrés. Quelles sont-elles?
Variation totale des scores = SC totale
variation intra-groupe = SC intra
variation inter-groupes = SC inter
L’ANOVA s’intéresse à la variance (écart à la moyenne). La variance fonctionne avec le carré des écarts sinon l’addition des écarts deviendrait nulle.
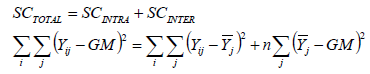
Comment calcule-t-on la somme de carré total dans l’ANOVA?
On additione l’écart au carré pour tous les sujets et groupes.
Le 143 ici est ma variation totale par rapport à ma grande moyenne. Ensuite je vais vouloir allé voir quel partie est dû à la variance de mes groupes ou de mes sujets
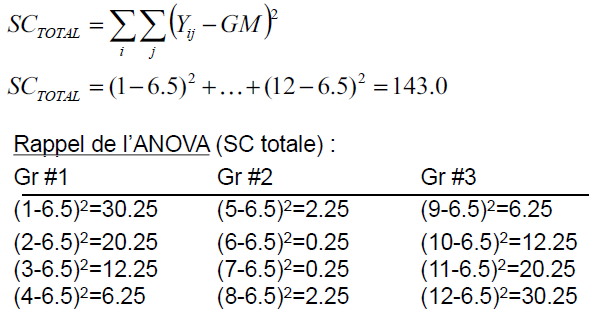
Comment calcule-t-on la somme de carré intra dans l’ANOVA?
SCintra = Variabilité des sujets dans les groupes.
Les sujets sont donc comparés par rapport à leur groupe (moyenne de leur groupe).

Dans un ANOVA, que signifie un SCtotal de 143 jumelé à un SCintra de 15?
L’essentielle de la variation (SCtotal: 143) est entre les groupes (SCinter: ?) pas entre les sujets (SCintra: 15)
Comment calcule-t-on la SCinter de l’ANOVA?
On fait la moyenne de chaque groupe vs la grande moyenne.
Quand je regarde des variations de moyennes, ça bouge pas mal moins vite que les variations de sujets. C’est pour ça qu’on ajoute le “n” (nombre de sujets par condition).

Dans un ANOVA, le rapport F permet de tester si la variance […]-groupes est significativement plus importante que la variance […]-groupe
Dans un ANOVA, le rapport F permet de tester si la variance inter-groupes (différences entre les groupes) est significativement plus importante que la variance intra-groupe (variabilité naturelle des scores)
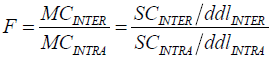
Comment calcule-t-on les degrés de libertés dans l’ANOVA?
- ddlinter: Nbr gr (p) - 1
- ddlintra: Cb d’observation par groupe sont libres de varier et quand mçeme obtenir le même résultat?Ici, j’ai 4 sujets par groupe (3 groupes). Donc j’ai p * (n-1) : (p=nbr groupe) (n = nb de personnes par groupe) = 9
- ddl : Combien de “sujets/groupes” peut varier pour obtenir quand même le même résultat (ex: Cb de groupes peuvent varier pour quand même obtenir 128 si j’ai 3 groupes. 2 gr) =
Quel est l’avantage de la MANOVA par rapport à l’ANOVA?
Généralement, quand j’ai un rapport de F non significatif c’est parce que mon intra est trop gros ou mon inter est trop petit.
Donc la MANOVA permet d’accroître la sensibilité (la puissance) des tests F de l’ANOVA en réduisant le terme d’erreur (MCINTRA)
-> Le terme d’erreur est ajusté par le retrait de la covariance entre la VD et la (les) covariable(s)
VRAI ou FAUX
L’ANCOVA permet un ‘appariement’ statistique de façon à produire des groupes
« comparables » selon les différences individuelles présentes (en raison de l’absence de répartition aléatoire). Elle peut donc être utilisée comme substitut à la méthode expérimentale.
FAUX
L’ANCOVA permet un ‘appariement’ statistique de façon à produire des groupes
« comparables » selon les différences individuelles présentes (en raison de l’absence de répartition aléatoire).
Attention! Ce n’est pas un substitut à la méthode expérimentale Un ajustement statistique n’est jamais autant convaincant qu’une vrai évaluation méthodologique.
Fonctionnement de la MANOVA:
Permet d’identifier les variables qui contribuent à un effet […] significatif (analyse stepdown) On retire à tour de rôle chaque VD en la transformant en […]. Lorsqu’une VD placée en covariable élimine l’effet significatif de la VI, nous pouvons conclure que cet effet significatif affectait surtout […].
Fonctionnement de la MANOVA:
Permet d’identifier les variables qui contribuent à un effet multivarié significatif (analyse stepdown) On retire à tour de rôle chaque VD en la transformant en covariable. Lorsqu’une VD placée en covariable élimine l’effet significatif de la VI, nous pouvons conclure que cet effet significatif affectait surtout cette VD.
Quelles sont les limites théoriques de la MANOVA et de l’ANCOVA? (5)
- Ne permet pas d’attribution causale
- Ne remplace pas la méthode expérimentale
- L’augmentation du nombre de paramètres dans le modèle provoque une diminution des degrés de liberté
- Le nombre de covariables devrait être restreint, et les covariables ne devraient pas être corrélées entre elles ou avec la VI
- Ça ne vaut pas la peine d’entrer des variables qui sont corrélées entre elles (redondance)
- L’interprétation de moyennes ajustées est toujours délicate (p.ex., ajusté selon sexe)
- Dans certains cas, l’ajustement fonctionne mais l’ajustement est bizzarement explicable de manière pratique. Un bon exemple est un ajustement pour le sexe (codé 1 2, moyenne de 1.59) qui ne représente pas la vie réelle.
Quelles sont les conditions d’utilisation de l’ANCOVA et de la MANOVA? (6)
- Taille d’échantillon
- 5 à 10 sujets par cellule (groupe)
- Il ne doit pas y avoir de donnée manquante sur la covariable, sinon l’observation au complet sera retirée (listwise deletion). Pourquoi? La covariable est un effet du modèle, qui est sous le contrôle de l’expérience (comme la variable indépendante)
- Normalité
- Absence de données extrêmes
- Linéarité des relations (entre VD et covariables, et les covariables entre elles)
- Homogénéité des variances entre les groupes (homoscédasticité)
- Homogénéité des pentes
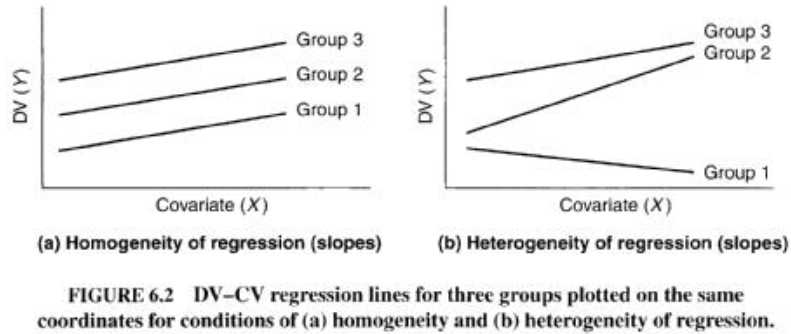
Expliquez le postulat d’homogénéité des pentes de l’ANCOVA et de la MANOVA.
La relation entre la VD et la covariable doit être similaire (même B) pour chaque cellule. Sinon, les moyennes de certains groupes seront sur/sous-ajustées.
Ce qui est important ici c’est que les pentes soient homogènes, pas d’importance pour l’intercept.
L’ajustement à rapport au coefficient de régression donc à la pente.On veut à peu près la même relation pour chaque pente. Donc a est positif pour chaque relation.
Pour b, les relations sont positifs ou négatifs, ça c’est problématique car dans certains groupes il va y avoir un sur et sous ajustement. L’analyse va partir comme si elle avait fait une régression sur tout groupe confondu donc si la direction des relations n’est pas similaire, on va avoir un problème.
Si ce postulat n’est pas respecté, on vient fausser nos résultats d’analyse
Comment choisi-t-on une bonne covariable dans l’ANCOVA et la MANOVA? (4)
- Choix théorique vs. empirique
- Elle doit avoir une bonne fidélité (Cronbach > .80)
- Elle doit présenter une relation linéaire avec la VD
- Il arrive dans certains cas où la relation existe mais elle n’est pas linéaire. Il y a d’autres analyses à faire à la place
- Si plusieurs covariables, elles ne doivent pas être trop corrélées ensemble (R2 < .50)
- Pas de redondance!
Expliquez ce qu’implique le choix théorique/empirique dans le choix de covariable dans les ANCOVA et MANOVA.
Si on se base sur la théorie et que finalement il n’y a pas de corrélation/association (ex: On inclut le sexe mais finalement ça change rien), bin l’ajustement va être nulle alors ça ne changera pas grand chose. Donc oui pour le choix théorique mais empirique peut donner une bonne idée aussi.
Si on se fie juste sur l’empirique et on rentre tout comme variable confondante bin une association peut être trouvé mais sans vrm être lié au problème.
Il faut un mix des deux. Il faut réfléchir à un fondement théorique à pourquoi ça pourrait être une variable confondante et avoir des preuves dans mon jeu de données qu’il y a une relation.
Qu’est-ce qu’un mythe statistique? Donnez un exemple.
Un mythe statistique est qu’une variable différente entre les groupes doit automatiquement être incluse comme covariable.
Exemple
Si mes participants présentent un âge moyen différent selon le groupe, l’âge doit être inclus comme covariable.
FAUX : L’inclusion de l’âge comme covariable va réduire les différences confondantes entre les groupes seulement si l’âge est associé à la VD!
VRAI ou FAUX
Variable confondante est une variable modératrice (interaction)
FAUX
Variable confondante N’EST PAS une variable modératrice (interaction) ou médiatrice
- *Une variable confondante :**
1. Doit être associée à la VI mais ne pas être une conséquence de la VI
2. Doit être associée à la VD mais ne pas être une conséquence de la VD
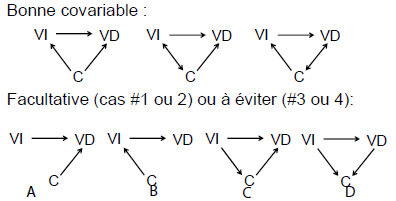
Expliquer cette image pour le choix d’une covariable en fonction de son influence sur la VD.
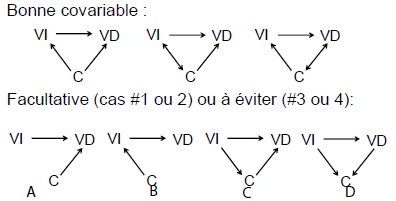
A et B: La covariable va compétitionner avec la VI
C. Exemple de médiation et non d’une covariable
D. Redondance. Je vais dénaturer mes groupes car je vais créer deux groupes (ex: deprimé vs non déprim) qui sont ajustés selon la covariable (dépression). Ça va donner deux groupes modérés après l’ajustement et donc confondre la relation
Expliquer la mécanique de l’ajustement utilisé selon le graphique ci-joint.
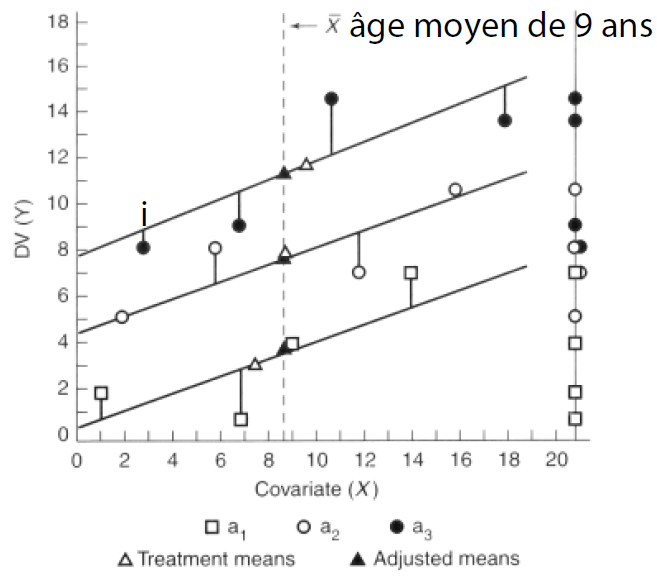
Axe Y: Variable dépendante (ex: Stress qui va de 0 à 18)
Axe X: Covariable (ex: Âge de 0 à 20 ans)
- *Treatment means:** Moyennes brutes
- *Adjusted means:** Moyennes ajustée
Les gens sont répartis en trois groupes (a1, a2, a3).
La droite verticale représente les scores qu'on donné les gens à la VD (on voit que le a1 donne le plus petit score stress, le a2 moyen et le a3 le plus grand). Donc ici (i) on a un enfant de 3 ans qui avait un score de 8 de stress.
On constate que les trois moyennes (brutes) de la VD sont différentes. OR, on ne peut pas les comparer sans les ajuster pour l’âge (covariable). Donc on ne peut pas l’utiliser pour l’instant. Donc ici je vais ajusté pour faire en sorte que l’âge ne soit plus un facteur confondant. Pour ce faire, on centralise nos données (mettre à zéro impossible ici donc on centralise à l’âge moyen (9ans) dans l’échantillon complet).
- > À partir de là, je vois que ma moyenne ajustée pour la VD a donc été baissée pour a3, le groupe a2 n’a pas besoin de baisser la moyene ajustée car il était déjà dans la bonne moyenne d’âge.
- > A1 devra être augmenté car ils étaient trop jeune en moyenne. Donc la moyenne brut de stress était de 3 et la moyenne ajustée est de 4 maintenant pour ce groupe.
- > Si je suis pire que mes collègues et je veux être ajusté en fonction que mes collègues, ma performance va être améliorée. Si je suis mieux que mes collègues, ma performance va être baissée. Si la relation entre la covariable et la VD était négative, est-ce que l’ajustement de la dernière phrase serait le même? Mon niveau final (stress) va être plus bas si je suis plus bas que mes collègues (plus jeune) lorsque j’ajuste.


















