1
Q
reason for clustering
A
categorize data without labels
2
Q
cluster searching
A
- search for closest cluster
- search within the cluster
** Note: much faster than searching each document
3
Q
k-means training
A
- initialize k random centers
- calculate points in each cluster
- recalculate the cluster centers using the mean
4
Q
responsibility
A
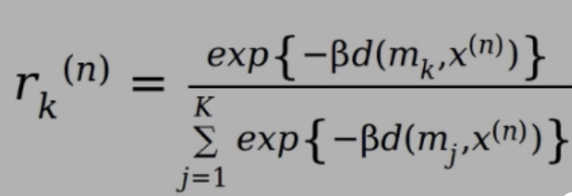
5
Q
fuzzy k-means (soft k-means) algorithm
A
- reflects confidence in cluster
- initialize k random centers
- calculate responsibilities (soft max)
- calculate mean responsibilities (hard k-means is where r is 0 or 1)
6
Q
k-means cost function
A
- Euclidean - sensitive to scale and K, K=N -> 0 cost
- Davies Bouldin index - low ‘inter’ std and high ‘intra’ std; lower better
7
Q
where k-means fails
A
- donut
- assymetric (high var) gaussian
- smaller cluster in bigger one
8
Q
k-means problems
A
- choice of k
- local minimum is bad in this case
- sensitive to initial clusters
- can only find spherical clusters
- does take density into account
9
Q
ideal k value
A
- where the steep meets the flat
- not at the minimum
10
Q
hierarchical (agglomerative) clustering
A
- greedy algorithm
- merge two closest points until you have 1 group with all of the points
- threshold the cluster intra distance
11
Q
joining cluster
A
- single linkage: min distance between any two points
- complete linkage: max distance b/w any two points
- mean distance (UPGMA): mean distance between all pts
- Wards: minimize increase in variance
12
Q
dendrogram
A
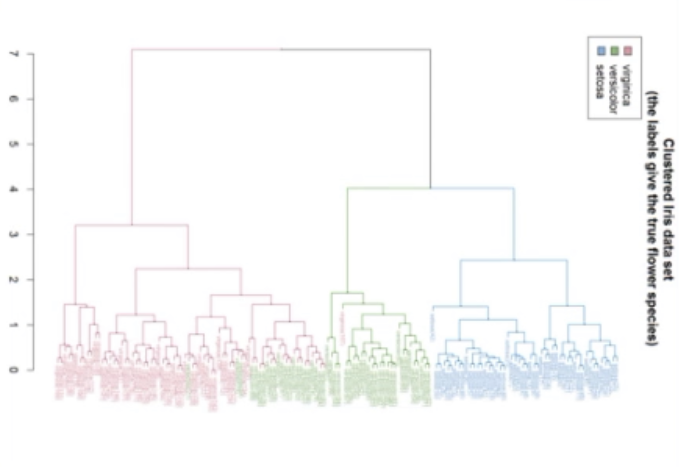
13
Q
distances equations
A

14
Q
valid distance metrics
A
- non-negative: d(x, y) ≥ 0, positive
- identity: (x, y) = 0 <=> x=y, definite
- symmetry: d(x, y) = d(y, x)
- subadditive: d(x, z) ≤ d(x, y) + d(y, z)
15
Q
self-organized maps
A
- apply competitive learning as opposed to error-correction learning
- dimension reduces to discretized representation of the input
- called a map
16
Q
gaussian mixure model (GMM)
A
- form of density estimation
- gives approximation of the probability distribution
- use when notice multimodal data
- p(x)=π1N(µ1,∑ 1)1+π2N(µ2,∑ 2)2
- π=probility x belongs to to Gaussian k
- π sums to 1
- introduce latent Z for which π=p(Z=k)
*
17
Q
GMM algorithm
A

18
Q
responsibility k-means v. GMM
A
- k-mean cluster use of softmax
- GMM uses normal times probabilities
19
Q
independent component analysis (ICA)
A
- special type of blind source separation
- cocktail party problem of listening in on one person’s speech in a noisy room
- data: x=(x1,…,xm)T
- hidden components: s=(s1,…,sn)T
- mixing matrix: W n by n
- unmixing matrix recovers source: W=A-1.
- generative model (noiseless): x=As
- noisy: x=As+n
*
20
Q
benefits of GMM over fuzzy k-means
A
- GMM has multiple π as opposed to one ß
- it can handle elliptical whereas fuzzy k-means needs to be spherical
21
Q
GMM v. Fuzzy K-means
A

22
Q
singular covariance problem
A
- close points approach 0
- division by 0 is singularity
- local minimum
23
Q
ways of dealing with singular covariance problem
A
- diagonal covariance -
- solution to singular covariance
- speed up computation (easy to take inverse)
- spherical gaussian
- shared covariance
- each gaussian has the same covariance
24
Q
diagonal covariance
A

25
kernel density estimation
fitting PDFs with kernels; can use GMM
26
expectation-maximization (EM)
* general version of GMM
* latent variables
* coordinated descent
* increasing likelihood guarantee (max likelihood)
27
dimensionality reduction
1) cleaner signal; 2) decreased transformation load -\> reduced time; 3) allow visualization of data
28
single value decomposition (SVD)

29
PCA
* Z=XQ
* rotates the data (changes eigenvector and values), doesn't change the length
* high variance = signal
* low variance = noise
* keep left most columns of Z (~95 %)
30
how does PCA help?
1. cleaner signal
2. decreased transformation load -\> reduced time
3. allow visualization of data
31
naive bayes connection to PCA
PCA makes IID assumption true
32
greedy layer-wise pretraining
* helps with supervised learning
* only objective of layer is to train itself
* only requires a few epochs of training to fine-tune
33
autoencoder
* J=|X-s(S(XW)W.T)|\*\*2
* non-linear PCA
* linear activation gives PCA
* predicts itself (auto=self)
* square error for x \< 0 and x \> 0
* cross-entropy works for 0 ≤ x ≤ 1
* different biases for hidden and output layers
* shared weights (type of regularization
34
types of autoencoders
1. Denoising autoencoder
2. Sparse autoencoder
3. Variational autoencoder (VAE)
4. Contractive autoencoder (CAE)
35
bottleneck network
* find useful and efficient representation
* compress V dimension into D in the encoding phase
36
stacking
* we only care about the "inner" representation
* discard the 2nd half each time
* each layer smaller in size
1. train an autoencoder on X with HL output Z;
2. train a 2nd autoencoder on Z;
3. repeat
37
denoising autencoder
* an autoencoder that is missing information
* attempt to address identity-function risk by randomly corrupting input
* its like training with dropout
* missing data not always represented by 0
* mask the cost in back propagation

38
sparse autoencoder
* when you train an autoencoder, the hidden units in the middle layer would fire (activate) too frequently, for most training samples
* sparsity constraint: lower the activation rate so that they only activate for a small fraction of the training examples
* sparse because each unit only activates to a certain type of inputs
39
how to reproduce missing data
* use autoencode or the likes
* *

40
recommender systems
* google, youtube, netflix
* use RBMs and autoencoders
*
41
naming convention
* Recommender
* N is instances
* M is movies
* K is latent variables
* Typical Deep Learning
* N is instances (same)
* M is hidden units
* K is number of classes
* D is input dimensions
42
boltzmann machine
* everything is connected to everything
* only works on trivial problems, unlike RBM
* non-tractable
43
restricted boltzmann machine (RBM)
* bipartite graph
* produces visible vector from hidden and vice versa
* assume each hidden and output is IID
* use sigmoid (to keep output 0-1)
* act just like autoencoders
* find latent variables
* greedy pretraining
* non-tractable, therefore, needs to be approximated hidden units only connected to the visible unit
* square error for all X
* cross-entropy works for 0 ≤ x ≤ 1
44
categorical RBM

45
categorical RBM shapes
* h = M
* V = D x K
* D is number of movies
* K is the number of classes
* W = D x K x M
* b = D x K
* x = M
46
deep belief network
deep network of stacked RBMs
47
latent variable
variable that is hidden
48
markov random field
* graph of states
* each node is a state
* state of each node only relies on adjacent node
49
relaxed bernouli constraint
in RBM,
1. threshold
2. let the values go to whatever
50
hidden markov model
# * unsupervised learning method
* models sequences & classifies
* modified using bayes rules to create separate model for each class
* choose class with the highest likelihood
51
HMM applications
1. recognizing male or female voice
2. NLP: macbook was created by "p(x|x-, x--)"
3. stock predicition
4. SEO and bounce rate optimization
5. speech to text: words to sound
52
markov property
* p(x | all time) = p(x | x-)
* strong assumption
53
joint probability
* chain rule of probability
* p(s3, s2, s1) = p(s3|s2)p(s2|s1)p(s1)
54
markov order
* 1st order - p(y2 | y1)
* 2nd order - p(y3 | y2, y1)
* 3rd order - p(y4 | y3, y2, y1)
55
markov model
* M states
* π = 1 x M, column vector
* A = M x M weights
* A(i, :).sum() = 1
56
smoothing
* add smoothing to account for unobserved
* p = (count(x)+λ)/(N+λµ0)
* can smooth average ratings too
* r = (∑xi+λµ0)/(N+λ)
57
HMM model
1. πi = probability of starting at state i
2. A(i, j)
1. state transition matrix
2. probability of going to state j from i
3. P(tag1|tag0)
4. if row sum to 1, A is markov matrix
3. B(j, k)
1. observation probability matrix
2. probability of observing k given j
3. p(word|tag)
58
double embedded
* layer 1: Markov model
* layer 2: choose observation
59
forward, forward-backward algorithm

60
backward, forward-backwards algorithm

61
forward backwards code

62
viterbi algorithm
* find the most probable hidden state sequence given the observed sequence
* the same as forward backward algorithm except taking the max instead of sum
* delta variable is like alpha
* psi is similar to delta but argmax instead and no B term
* have to backtrack the states
63
vertirbi initialization

64
vertirbi recursion

65
vertirbi termination

66
Baum-Welch algorithm
* Is similar to Gaussian mixture models
* Use expectation maximization (iterative algorithm) instead of maximum likelihood
* review at some other date, it is a very expensive algorithm and should be avoided if possible
67
variational autoencoder
* Bayersian ML + Deep Learning
68
generative adversarial network (GAN)
* 2 networks competing against eachother
*
69
generative versus discriminitive
* generative: P(X|Y)
* discriminitive: P(Y|X)
* hard to tell what is happening with weights
* not satisfactorial to statistician
* research shows that discriminitive works better
70
types of recommender systems
* autorec: uses autoencoder to recommend missing data
* non-personalized:
* shows popular items
* confidence
* takes time into account
* product associations
* collaborative filter: what YOU and what OTHERS similar to you like
71
matrix factorization
* SVD example is an: X=WSUT
* S is diagonal matrix of the variances
* more variance = more important
* we only want square error where rating is known
* break up X into components for less parameters stored
* use K size ~50-100
* Aij=log(Xij)~=wiTu
72
account for age in recommender system?
* hacker news: penalty\*(ups-downs-1)0.8/(age+2)gravity
* gravity = 1.8
* age in hours
* business rules:
* penalize self, controversial and popular websites posts
* reddit: sign(ups-downs)log{max(1, |ups-downs|)}+age/45000
* age in seconds
73
ranking with big systems
* discard users w/ few movies in common
* sum over nearest neighbors
* take ones with higheset weights
* say k = 25 to 50
* closest absolute correlation
* closest raw correlation
* or use everybody
74
training matrix factorization
* J = ∑(tij-wiTuj)
* dJ/dwi = ∑(tij-wiTuj)uj=∑ujujTwi
* wi = (∑ujujT)-1∑rijujT
* j is of Ψ
* dJ/duj = ∑(tij-wiTuj)uj=∑ujujTwi
* uj = (∑wjwjT)-1∑rijwi
* j is of Ω
* but really, rij=wiTuj+bi+cj+µ
* cj = rij-wiTuj+bi+µ
* bi = rij-wiTuj+cj+µ
* µ = global average
